逆向实操、x86/x64汇编、IDA pro静态分析 |
您所在的位置:网站首页 › ida修改exe jmp › 逆向实操、x86/x64汇编、IDA pro静态分析 |
逆向实操、x86/x64汇编、IDA pro静态分析
 逆向实操汇编 《汇编语言》,王爽 《天书夜读》邵坚磊等 《Intel汇编指令集手册》 基础学习汇编的原则不推荐写纯汇编程序,一般都是通过_asm{}方式嵌入部分汇编代码学习汇编的目的是:解底层,调试,逆向分.c-编译->.s-汇编→.o(linux平台)/.obj(windows平台)-链接->.elf/.exeC源程序(.c/.cpp)->汇编程序(.S) ->二进制(.exe/.dll/.sys或者.elf/.so)->加壳保护冯.诺伊曼体系图灵在理论上证明了计算机可以被制造出来冯.诺伊曼将理论中的计算机变成现实--冯.诺伊曼体系(存储程序) Cpu:ALU(算法逻辑运行单元)+FPU(浮点数计算单元)+CPU Registers(存放数据,地址,代码)Cpu CacheMemory内存磁盘 逆向实操汇编 《汇编语言》,王爽 《天书夜读》邵坚磊等 《Intel汇编指令集手册》 基础学习汇编的原则不推荐写纯汇编程序,一般都是通过_asm{}方式嵌入部分汇编代码学习汇编的目的是:解底层,调试,逆向分.c-编译->.s-汇编→.o(linux平台)/.obj(windows平台)-链接->.elf/.exeC源程序(.c/.cpp)->汇编程序(.S) ->二进制(.exe/.dll/.sys或者.elf/.so)->加壳保护冯.诺伊曼体系图灵在理论上证明了计算机可以被制造出来冯.诺伊曼将理论中的计算机变成现实--冯.诺伊曼体系(存储程序) Cpu:ALU(算法逻辑运行单元)+FPU(浮点数计算单元)+CPU Registers(存放数据,地址,代码)Cpu CacheMemory内存磁盘 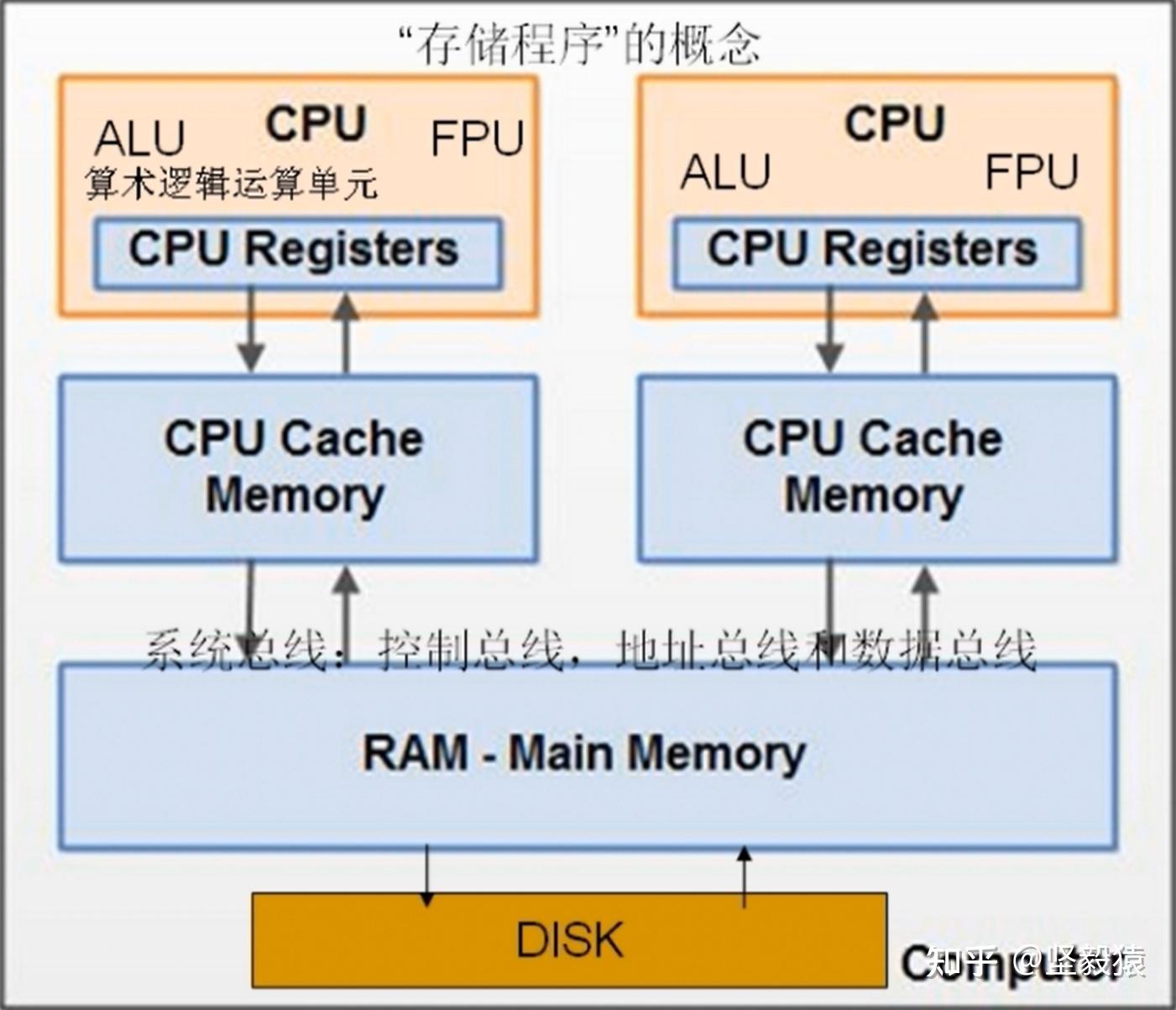 寄存器寄存器的位数:1次能存储和处理的位数,也是计算机的位数(16/32/64位计算机) 16位,ax32位,eax64位,rax32位汇编寄存器通用寄存器(通用指的是可以存放任何数据,寄存器名字不区分大小写): EAX,EBX,ECX, EDX源变址目标变址寄存器: 变表示ESI和EDI会自++/--ESIEDl(S表示source,D表示Destination)栈相关寄存器: SS(只要在16位系统才有用,在32/64位系统在SS存放的是个常数),ESP(栈顶),EBP(栈底)代码段寄存器,程序指令寄存器: CS(代码段的起始地址),EIP(下一条要执行指令的地址)数据段寄存器: DS(常与ESI寄存器结合使用)(data)附加段寄存器: ES(常与EDI寄存器集合使用)(extra)控制寄存器: CR0-CR3(control)CR0包括指示处理器工作方式的控制位,包含启用和禁止分页管理机制的控制位,包含控制浮点协处理器操作的控制位CR1被保留,供今后开发的处理器使用。CR2及CR3由分页管理机制使用。CR2用于发生页异常时报告出错信息。当发生页异常时,处理器把引起员异常的线性地址保存在CR2中。操作系统中的页异常处理程序可以检查CR2的内容,从而查出线性地址空间中的哪一页引起本次异常.CR3用于保存页目录表页面的物理地址,因此被称为PDBR。系统地址寄存器: GDTRLDTRIDTR,中断描述符表寄存器TR寄存器包含了当前正在CPU运行的进程的TSSD(任务段描述符)选择符Flag标志寄存器 ZF零标志,零标志ZF用来反映运算结果是否为0。如果运算结果为0,则其值为1,否则其值为0;AF辅助进位标志,运算过程中第三位有进位值,置AF=1,否则,AF=0;PF奇偶标志,当结果操作数中偶数个"1",置PF=1,否则,PF=0;SF符号标志,当结果为负时,SF=1;否则,SF=0。溢出时情形例外;CF进/借位标志,最高有效位产生进位值,例如,执行加法指令的,MSB最高位)有进位,置CF=1;否,CF=0;OF溢出标志,若操作数结果超出了机器能表示的范围,则产生溢出,置OF=1,否则,OF=0。在win2000以上操作系统对于ebx,esi,edi拿来就用,没有进行保护和恢复,如果你的程序中使用了这几个寄存器,请一定先压栈,用完后恢复。64位汇编寄存器在64位系统中,寄存器的表示方法为: 寄存器作用一样,就是保存数据的位数增加了(16位ax->32位eax->64位rax),名字加一个r通用寄存器:rax, rbx,rcx, rdx栈寄存器:rsp,rbpr8,r9,r10,r11,r12,r13,r14,r15(这8个是64位汇编中新增加的) -fastcall传递参数的寄存器:(rdx,rcx,) r8, r9(arguments) Scratch寄存器:(rbx),r12,r13, r14, r15(scratch-乱写),即可以随时改写的奇存器汇编中的整数intel汇编: 1aH/0ffffh(后面加,16进制)17O(8进制)12D(10进制)110B(2进制)C语言 0x(前面加,16进制)0(8进制)(什么都没加,16进制)(C语言中不存在2进制表示方式)CPU,寄存器,和内存之间的关系 寄存器寄存器的位数:1次能存储和处理的位数,也是计算机的位数(16/32/64位计算机) 16位,ax32位,eax64位,rax32位汇编寄存器通用寄存器(通用指的是可以存放任何数据,寄存器名字不区分大小写): EAX,EBX,ECX, EDX源变址目标变址寄存器: 变表示ESI和EDI会自++/--ESIEDl(S表示source,D表示Destination)栈相关寄存器: SS(只要在16位系统才有用,在32/64位系统在SS存放的是个常数),ESP(栈顶),EBP(栈底)代码段寄存器,程序指令寄存器: CS(代码段的起始地址),EIP(下一条要执行指令的地址)数据段寄存器: DS(常与ESI寄存器结合使用)(data)附加段寄存器: ES(常与EDI寄存器集合使用)(extra)控制寄存器: CR0-CR3(control)CR0包括指示处理器工作方式的控制位,包含启用和禁止分页管理机制的控制位,包含控制浮点协处理器操作的控制位CR1被保留,供今后开发的处理器使用。CR2及CR3由分页管理机制使用。CR2用于发生页异常时报告出错信息。当发生页异常时,处理器把引起员异常的线性地址保存在CR2中。操作系统中的页异常处理程序可以检查CR2的内容,从而查出线性地址空间中的哪一页引起本次异常.CR3用于保存页目录表页面的物理地址,因此被称为PDBR。系统地址寄存器: GDTRLDTRIDTR,中断描述符表寄存器TR寄存器包含了当前正在CPU运行的进程的TSSD(任务段描述符)选择符Flag标志寄存器 ZF零标志,零标志ZF用来反映运算结果是否为0。如果运算结果为0,则其值为1,否则其值为0;AF辅助进位标志,运算过程中第三位有进位值,置AF=1,否则,AF=0;PF奇偶标志,当结果操作数中偶数个"1",置PF=1,否则,PF=0;SF符号标志,当结果为负时,SF=1;否则,SF=0。溢出时情形例外;CF进/借位标志,最高有效位产生进位值,例如,执行加法指令的,MSB最高位)有进位,置CF=1;否,CF=0;OF溢出标志,若操作数结果超出了机器能表示的范围,则产生溢出,置OF=1,否则,OF=0。在win2000以上操作系统对于ebx,esi,edi拿来就用,没有进行保护和恢复,如果你的程序中使用了这几个寄存器,请一定先压栈,用完后恢复。64位汇编寄存器在64位系统中,寄存器的表示方法为: 寄存器作用一样,就是保存数据的位数增加了(16位ax->32位eax->64位rax),名字加一个r通用寄存器:rax, rbx,rcx, rdx栈寄存器:rsp,rbpr8,r9,r10,r11,r12,r13,r14,r15(这8个是64位汇编中新增加的) -fastcall传递参数的寄存器:(rdx,rcx,) r8, r9(arguments) Scratch寄存器:(rbx),r12,r13, r14, r15(scratch-乱写),即可以随时改写的奇存器汇编中的整数intel汇编: 1aH/0ffffh(后面加,16进制)17O(8进制)12D(10进制)110B(2进制)C语言 0x(前面加,16进制)0(8进制)(什么都没加,16进制)(C语言中不存在2进制表示方式)CPU,寄存器,和内存之间的关系 内存寻址16位汇编-Hello worlddemodata segment ;这里定义一个数据段
str db 'hello world$’ ;这里用内存存放字节数据"hellow world",$用来判断字符串是否输出完毕
data ends ;数据段的结束标志
code 'segment' ;这里定义了一个代码段
assume cs:code, ds:data ;程序中定义的段与对应的段寄存器关联起来
start: ;start标号是程序的开始位置
mov ax,data
mov ds,ax ;这里把数据段的地址放到数据段寄存器ds中
lea dx,str ;dx中放将要显示数据的偏移地址
mov ah,9h ;al(ax低8位) ah(ax高8位)
int 21h ;调用21号中断的9号功能来显示字符串
mov ah,4ch
int 21h ;程序返回
code ends ;代码段的结束语
end start ;定义程序从哪个标号处开始执行16位汇编开发编译平台:masm,dosbox 安装masm包(含masm,link,debug等工)c:\masm安装并启动dosbox0.74mount c: c:\masm5切换到masm安装路径:直接输入c:编辑a.asm汇编代码编译 masm a.asm Link a.obj debug a.exeVC中开发调试汇编代码//x86
int_tmain(int argc,_TCHAR* arg[])
{
char str[]="hello world";
char format[]="%s \n";
//printf("%s\n",str)
__asm
{
LEA eax,str
PUSH eax
LEA eax,format
PUSH eax
Mov ebx,[pintf]
call ebx
add esp,8 //栈平衡,入栈时是-8,因为栈是从高地址向地址增长
}
return 0;
}
//x64中: 需要把汇编独立写在一个文件中
汇编指令汇编指令分类 传送指令:mov/lea/push/pop算术指令逻辑指令串操作指令控制转移指令(jmp,call,int)处理机控制指令汇编指令操作对象:立即数(常量),内存,寄存器汇编指令构成 1.汇编指令:机器码助记符,有对应的机器码,比如mov指令等;2.伪指令:无对应的机器码,编译器执行比如assume语句;3.其他符号:+,-,*,/,由编译器识别,无对应机器码。常见机器码: short jump ebnear jump e9far jump eaje/jz 74jne/jnz 75nop 90int 3 ccret c3call eax d0ffjmp esp e4ff简单指令集和复杂指令集1.指令集 RISC指令集(reduced instruction set computer,简单的指令集)只提供很有限的操作,基本上单周期执行每条指令,其指令长度也是固定(一般4个字节)。CISC指令(complex instruction set computer,复杂的指令集)复杂丰富,功耗大,长度不固定(1到6个字节)2.Load-Store 结构 在RISC 中,CPU并不会对内存中的数据进行操作,所有的计算都要求在寄存器中完成。而寄存器和内存的通信则由单独的指令来完成。而在CISC中,CPU是可以直接对内存进行操作的。3.更多的寄存器 和CISC相比,基于RISC的处理器有更多的通用寄存器可以使用,且每个寄存器都可以进行数据存储或者寻址。4.RISC指令集能够非常有效地适合于采用流水线、超流水线和超标量技术,从而实现指令级并行操作,提高处理器的性能。5.x86是cisc代表,arm,Macintosh是risc代表6.CISC存在的问题:指令系统庞大,指令功能复杂,指令格式、寻址方式多;执行速度慢;难以优化编译,编译程序复杂;80%的指令在20%的运行时间使用;无法并行;无法兼容; 内存寻址16位汇编-Hello worlddemodata segment ;这里定义一个数据段
str db 'hello world$’ ;这里用内存存放字节数据"hellow world",$用来判断字符串是否输出完毕
data ends ;数据段的结束标志
code 'segment' ;这里定义了一个代码段
assume cs:code, ds:data ;程序中定义的段与对应的段寄存器关联起来
start: ;start标号是程序的开始位置
mov ax,data
mov ds,ax ;这里把数据段的地址放到数据段寄存器ds中
lea dx,str ;dx中放将要显示数据的偏移地址
mov ah,9h ;al(ax低8位) ah(ax高8位)
int 21h ;调用21号中断的9号功能来显示字符串
mov ah,4ch
int 21h ;程序返回
code ends ;代码段的结束语
end start ;定义程序从哪个标号处开始执行16位汇编开发编译平台:masm,dosbox 安装masm包(含masm,link,debug等工)c:\masm安装并启动dosbox0.74mount c: c:\masm5切换到masm安装路径:直接输入c:编辑a.asm汇编代码编译 masm a.asm Link a.obj debug a.exeVC中开发调试汇编代码//x86
int_tmain(int argc,_TCHAR* arg[])
{
char str[]="hello world";
char format[]="%s \n";
//printf("%s\n",str)
__asm
{
LEA eax,str
PUSH eax
LEA eax,format
PUSH eax
Mov ebx,[pintf]
call ebx
add esp,8 //栈平衡,入栈时是-8,因为栈是从高地址向地址增长
}
return 0;
}
//x64中: 需要把汇编独立写在一个文件中
汇编指令汇编指令分类 传送指令:mov/lea/push/pop算术指令逻辑指令串操作指令控制转移指令(jmp,call,int)处理机控制指令汇编指令操作对象:立即数(常量),内存,寄存器汇编指令构成 1.汇编指令:机器码助记符,有对应的机器码,比如mov指令等;2.伪指令:无对应的机器码,编译器执行比如assume语句;3.其他符号:+,-,*,/,由编译器识别,无对应机器码。常见机器码: short jump ebnear jump e9far jump eaje/jz 74jne/jnz 75nop 90int 3 ccret c3call eax d0ffjmp esp e4ff简单指令集和复杂指令集1.指令集 RISC指令集(reduced instruction set computer,简单的指令集)只提供很有限的操作,基本上单周期执行每条指令,其指令长度也是固定(一般4个字节)。CISC指令(complex instruction set computer,复杂的指令集)复杂丰富,功耗大,长度不固定(1到6个字节)2.Load-Store 结构 在RISC 中,CPU并不会对内存中的数据进行操作,所有的计算都要求在寄存器中完成。而寄存器和内存的通信则由单独的指令来完成。而在CISC中,CPU是可以直接对内存进行操作的。3.更多的寄存器 和CISC相比,基于RISC的处理器有更多的通用寄存器可以使用,且每个寄存器都可以进行数据存储或者寻址。4.RISC指令集能够非常有效地适合于采用流水线、超流水线和超标量技术,从而实现指令级并行操作,提高处理器的性能。5.x86是cisc代表,arm,Macintosh是risc代表6.CISC存在的问题:指令系统庞大,指令功能复杂,指令格式、寻址方式多;执行速度慢;难以优化编译,编译程序复杂;80%的指令在20%的运行时间使用;无法并行;无法兼容;  传送指令movMOV DST,SRCMOV Reg/Mem, Reg/Mem/lmm Reg-Register(寄存器)Mem-Menory(存储器)lmm-lmmediate(立即数)eg:;段寄存器之间不能用MOV指令直接传送
mov eax,5
mov ds,eax ;正确
mov ds,es ;错误,据说是设计寄存器的时候电路不同,电路上不通
mov ds,5 ;错误
mov ax,word ptr value
mov eax,dword ptr value
mov al,byte ptr value
这里的word ptr/dword ptr/byte ptr实际上是指获取value的宽度(分别对应2字节,4字节和1个字节
MOV EAX,DWORD PTR SS:[EBP+1C] ;把
ebp-1C地址存放的值给eax,
;类似C语言中的DWORD *p = EBP-1C;eax = *p;
MOV DWORD PTR DS:[ESI+1C],EAX;
;类似C语言中DWORD *p = ESI+1C;eax = *p;PUSH/POPpush reg/mem/seg ;ss:[sp] = reg/mem/seg; sp = sp-2
pop reg/seg/mem ;sp = sp+2; reg/seg/mem = ss:[sp]
;PUSH进栈指令 格式为:PUSH SRC
push eax ;等价于mov [esp],eax;sub esp 4
;POP出栈指令 格式为:POP DST
pop eax ;等价于add esp 4;mov eax,[eax]
push AX
PUSH [2000H]
PUSH CS
POP AX
POP[2000H]
POP SSlea: load effective addressmov eax,[00400000];DWORD *p = 00400000; eax = *p
lea eax,[00400000];eax = 00400000
LEA EAX,[EBX+ECX*2+1] ;eax = ebx+ecx*2+1
mov eax, ebxtecx*2+1 ;不能这样写,mov不能跟表达式
mov eax,[ebx+edx+1] ;DWORD *p = ebx+edx*2+1 ;eax = *p
int val = 10;
char *s = "hello world";
int a = {1,2,3,4,5};
__asm
{
lea eax,val //等同lea eax,[val],都把val的地址放到eax寄存器
mov eax,val //等同mov eax,[val],都是把val的值放到eax寄存器
mov eax,s //等同于mov eax,[s],都是把s的值放到eax
lea eax,s //等同于lea eax,[s],都是把s的地址放到eax中
lea eax,[ebx+edx+1]
mov eax,[ebx+edx+1]
lea eax,a //把数组首地址存放eax
mov ebx,a //把a[0]存放到ebx
mov ecx,[ea×] //把eax地址的内存值
lea edx,[eax] //把eax直接放入edx
mov edx,[eax] //把eax地址的内存值
}
标志寄存器操作用来备份和恢复标志寄存器LAHF(Load AH with flags)flags送AH 用于将标志寄存器的低八位送入AH,即将标志寄存器FLAGS中的SF、ZF、A PF、CF五个标志位分别传送到AH的对应位(八位中有三位是光效的)SAHF(store AH into flags)AH送标志寄存器PUSHF(push the flags)标志进栈push eflagsPOPF(pop the flags)标志出栈pop eflags 传送指令movMOV DST,SRCMOV Reg/Mem, Reg/Mem/lmm Reg-Register(寄存器)Mem-Menory(存储器)lmm-lmmediate(立即数)eg:;段寄存器之间不能用MOV指令直接传送
mov eax,5
mov ds,eax ;正确
mov ds,es ;错误,据说是设计寄存器的时候电路不同,电路上不通
mov ds,5 ;错误
mov ax,word ptr value
mov eax,dword ptr value
mov al,byte ptr value
这里的word ptr/dword ptr/byte ptr实际上是指获取value的宽度(分别对应2字节,4字节和1个字节
MOV EAX,DWORD PTR SS:[EBP+1C] ;把
ebp-1C地址存放的值给eax,
;类似C语言中的DWORD *p = EBP-1C;eax = *p;
MOV DWORD PTR DS:[ESI+1C],EAX;
;类似C语言中DWORD *p = ESI+1C;eax = *p;PUSH/POPpush reg/mem/seg ;ss:[sp] = reg/mem/seg; sp = sp-2
pop reg/seg/mem ;sp = sp+2; reg/seg/mem = ss:[sp]
;PUSH进栈指令 格式为:PUSH SRC
push eax ;等价于mov [esp],eax;sub esp 4
;POP出栈指令 格式为:POP DST
pop eax ;等价于add esp 4;mov eax,[eax]
push AX
PUSH [2000H]
PUSH CS
POP AX
POP[2000H]
POP SSlea: load effective addressmov eax,[00400000];DWORD *p = 00400000; eax = *p
lea eax,[00400000];eax = 00400000
LEA EAX,[EBX+ECX*2+1] ;eax = ebx+ecx*2+1
mov eax, ebxtecx*2+1 ;不能这样写,mov不能跟表达式
mov eax,[ebx+edx+1] ;DWORD *p = ebx+edx*2+1 ;eax = *p
int val = 10;
char *s = "hello world";
int a = {1,2,3,4,5};
__asm
{
lea eax,val //等同lea eax,[val],都把val的地址放到eax寄存器
mov eax,val //等同mov eax,[val],都是把val的值放到eax寄存器
mov eax,s //等同于mov eax,[s],都是把s的值放到eax
lea eax,s //等同于lea eax,[s],都是把s的地址放到eax中
lea eax,[ebx+edx+1]
mov eax,[ebx+edx+1]
lea eax,a //把数组首地址存放eax
mov ebx,a //把a[0]存放到ebx
mov ecx,[ea×] //把eax地址的内存值
lea edx,[eax] //把eax直接放入edx
mov edx,[eax] //把eax地址的内存值
}
标志寄存器操作用来备份和恢复标志寄存器LAHF(Load AH with flags)flags送AH 用于将标志寄存器的低八位送入AH,即将标志寄存器FLAGS中的SF、ZF、A PF、CF五个标志位分别传送到AH的对应位(八位中有三位是光效的)SAHF(store AH into flags)AH送标志寄存器PUSHF(push the flags)标志进栈push eflagsPOPF(pop the flags)标志出栈pop eflags  算术指令ADD(add)加法add eax,1 ;eax = eax+1
add eax,ebx ;eax = eax + ebx
add Leax],ebx ;*eax= *eax + ebx
add eax,[ebx] ;eax = eax + *ebADC(add with carry)带进位加法adc eax,1 ;eax = eax + 1 + CF
;add和adc是否有区别取决于在计算过程中cf寄存器是否为1
xor eax,eax
add eax,1
xor eax,eax
adx eax,1
;两者没有区别INC(increment)加1DEC(Decrement)减1inc eax ; eax = eax+1
dec eax ; eax = eax-1SUB(subtract)减法SBB(subtract with borrow)带借位减法 (DST)=(DST)-(SRC)-CF,其中CF为进位的值sub eax, ebx ;eax = eax-ebx
sbb eax,5 ;eax = eax-5-CF
;ADC: 同下
;SBB:将DX:AX中存放的32位无符号数减去BX尚的16位无符号数
SUB AX,BX ;结果的低16位,如果AX小于BX将产生借位,导致CF=1
SBB DX,0 ;高16位-CF,若前一步出现借位,则据此调整高16位的内容NEG(Negate)求补(把正变负,把负变正) 算术指令ADD(add)加法add eax,1 ;eax = eax+1
add eax,ebx ;eax = eax + ebx
add Leax],ebx ;*eax= *eax + ebx
add eax,[ebx] ;eax = eax + *ebADC(add with carry)带进位加法adc eax,1 ;eax = eax + 1 + CF
;add和adc是否有区别取决于在计算过程中cf寄存器是否为1
xor eax,eax
add eax,1
xor eax,eax
adx eax,1
;两者没有区别INC(increment)加1DEC(Decrement)减1inc eax ; eax = eax+1
dec eax ; eax = eax-1SUB(subtract)减法SBB(subtract with borrow)带借位减法 (DST)=(DST)-(SRC)-CF,其中CF为进位的值sub eax, ebx ;eax = eax-ebx
sbb eax,5 ;eax = eax-5-CF
;ADC: 同下
;SBB:将DX:AX中存放的32位无符号数减去BX尚的16位无符号数
SUB AX,BX ;结果的低16位,如果AX小于BX将产生借位,导致CF=1
SBB DX,0 ;高16位-CF,若前一步出现借位,则据此调整高16位的内容NEG(Negate)求补(把正变负,把负变正)  neg eax ;eax = 0-eaxCMP(Compare)比较,相减cmp eax,5 ;eax-5,只影响标志寄存器,不会修改eax的值
jz L1 ;为0
jnz L2 ;不为0
L1:
...
L2:
...MUL(Unsigned Multiple)无符号数乘法 neg eax ;eax = 0-eaxCMP(Compare)比较,相减cmp eax,5 ;eax-5,只影响标志寄存器,不会修改eax的值
jz L1 ;为0
jnz L2 ;不为0
L1:
...
L2:
...MUL(Unsigned Multiple)无符号数乘法  IMUL(Signed Multiple)带符号数乘法;imul 1个操作数
imul al ;ax = al*al
imul bx ;dx:ax = ax*bx
imul ebx ;edx:eax = eax*ebx
imul dword ptr [ebx] ;edx:eax = eax*[ebx]
;5*6
mov eax,5;
mov ebx,6;
imul ebx ;edx:eax = eax*ebx
;imul 2个操作数
imul al r/m8 ;ax = al*r/m8
;imul 3个操作数
imul r32,r/m32,imm32 ;r32 = r/m32*imm32 IMUL(Signed Multiple)带符号数乘法;imul 1个操作数
imul al ;ax = al*al
imul bx ;dx:ax = ax*bx
imul ebx ;edx:eax = eax*ebx
imul dword ptr [ebx] ;edx:eax = eax*[ebx]
;5*6
mov eax,5;
mov ebx,6;
imul ebx ;edx:eax = eax*ebx
;imul 2个操作数
imul al r/m8 ;ax = al*r/m8
;imul 3个操作数
imul r32,r/m32,imm32 ;r32 = r/m32*imm32-DIV(Unsigned divide)无符号数除法  div ebx ; eax = (edx:eax)/ebx edx = (edx:eax)%ebx
;100/2
xor edx, edx ;高32位置0
mov eax,100
mov ebx,2
div ebxIDIV(Signed divide)带符号数除法 与 DIV一样的 div ebx ; eax = (edx:eax)/ebx edx = (edx:eax)%ebx
;100/2
xor edx, edx ;高32位置0
mov eax,100
mov ebx,2
div ebxIDIV(Signed divide)带符号数除法 与 DIV一样的 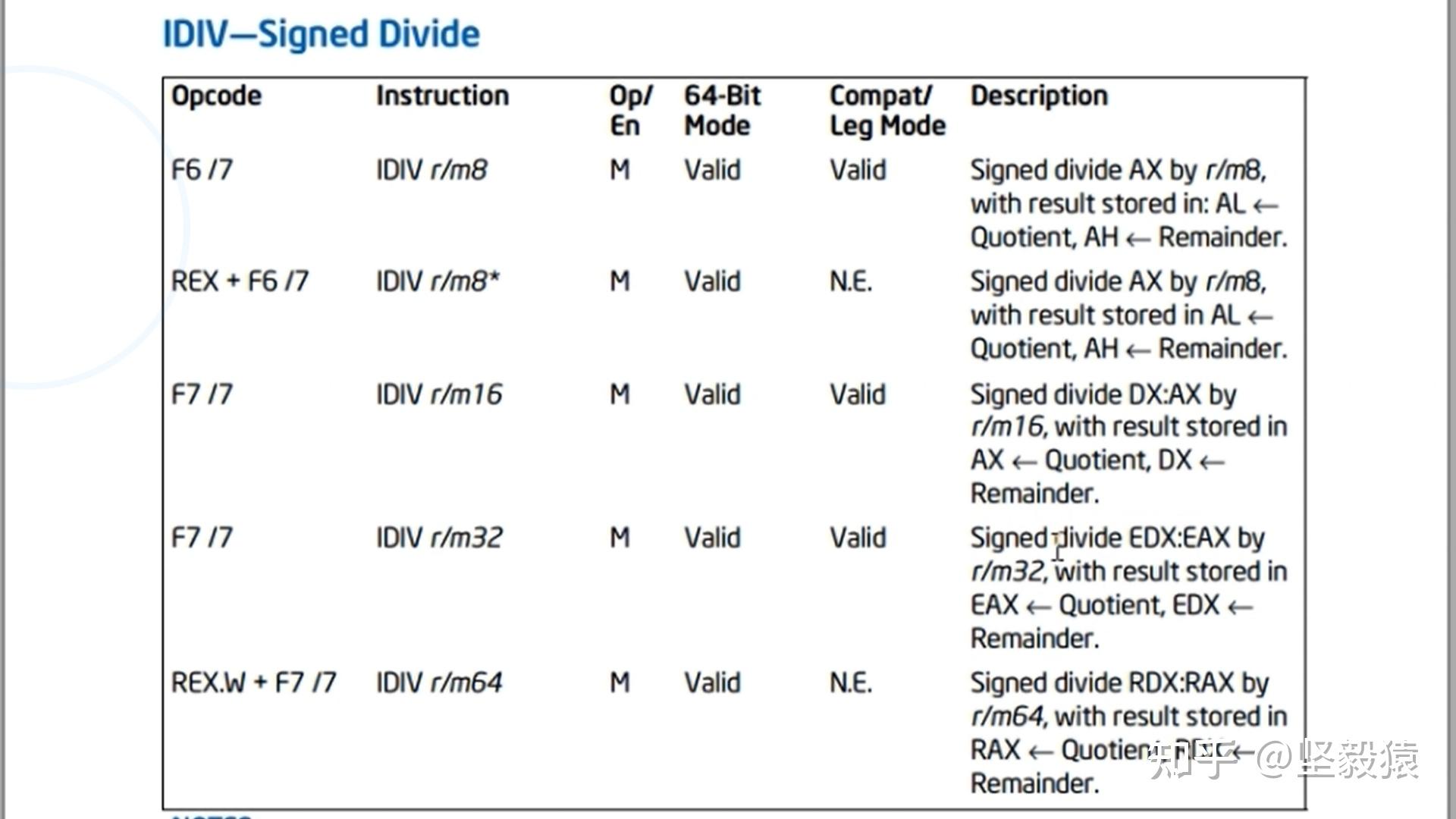 CBW(Convert byte to word)字节转换为字CWD(Contert word to double word)字转换为双字;用符号位去填充
mov al 10001101B;
CBW al ; ax = 11111111 10001101B
mov ax 12H;
CBW ax ; eax = FF12H用汇编实现+-*/int add_asm(int x,int y)
{
__asm
{
mov eax,x
mov ebx,y
add eax,ebx //函数返回值是放在eax中的
}
}
int sub_asm(int x,int y)
{
__asm
{
mov eax,x
sub eax,y //函数返回值是放在eax中的
}
}
int imul_asm(int x,int y)
{
__asm
{
mov eax,x
mov ebx,y
imul ebx //函数返回值是放在eax中的,edx的值怎么返回?假设不会结果不会超过4Byte,
//如果超过4Byte,在函数中定义多一个,传入参数的指针,edx部分可以存放在指针指向的变量来返回
}
}
int idiv_asm(int x,int y,int *r)
{
__asm
{
xor edx,0
mov eax,x
idiv y //(edx:eax)/y-->q-->eax,r-->edx
mov ebx,r
mov [ebx],edx //r
}
}
逻辑指令逻辑(位)运算AND(and) 与OR(or) 或NOT(not) 取反XOR(exclusive or) 异或and eax,1 ;eax = eax&1
or eax,1 ;eax = eax|1
not eax ;eax = ~eax
xor eax,eax ;eax= eax^eax
xor eax,ebx ;eax = eax^ebxTEST(test) 测试:(DST)&(SRC) test两个操作数相与的结果不保存,只根据其特征置条件码(影响EFLAGS寄存器ZF位,配合jz/jnz等条件跳转指令)Mov eax,2
Test eax,1 ;10&01=0
jz L1
L1:
xor eax,eax
L2:
mov eax,1移位运算SHL(shift logical left) 逻辑左移SAL(shift arithmetic left) 算术左移,与shl一样SHR(shift logical right) 逻辑右移SAR(shift arithmetic right) 算术右移ROL(Rotate left) 循环左移ROR(Rotate right) 循环右移RCL(Rotate left through carry) 带进位循环左移RCR(Rotate right through carry) 带进位循环右移;格式: SHL OPR,CNT(其余的类似)
;其中OPR可以是除立即数以外的任何寻址方式。移位次数由CNT决定,CNT需要放在CL(CX寄存器的低8位)寄存器中
mov al 00110011B
mov cl,3
shl al cl ; al = 11001100B 逻辑左移
sal al cl ; al = 11001100B 算术左移(C语言中对应的左移)
shr al cl; al = 00001100B 逻辑右移(左边用0填充)
sar al cl ; al = 11001100B 算术右移(左边用符号位填充)(C语言中对应的右移)
shr al cl ; al = 10011001B 循环左移
shr al cl ; al = 01100110B 循环右移
mov cl,1
clc ; CF = 0
mov al,88h ; CF,AL = 0 10001000b
rcl al,cl ; CF,AL = 1 00010000b
rcl a1,cl ; CF,AL = 0 00100001b
;rcr 同理用汇编实现算术左/右移/// xy
int sar_asm(int x,int y)
{
__asm
{
mov eax,x
mov cl,byte ptr y //不会超过127的,目前还没有128位系统比不通用
sar eax,cl
}
}
串操作指令movsMOVS BYTE PTR[DI],BYTE PTR[SI](双字) MOVSB(字节)MOVSW(字)执行的操作: 1.((DI))空:栈顶指针指向下一个入栈的有效数据项,递减:栈往低地址生长,栈的增长方向和内存的增长方向相反入栈时:先存数据,栈顶指针再减;出栈时:栈顶指针先加,再取数据;push eax
//等价于:
mov [esp],eax
sub esp 4
pop eax
//等价于
add esp,4
mov eax,[esp]
满递增栈(FA) CBW(Convert byte to word)字节转换为字CWD(Contert word to double word)字转换为双字;用符号位去填充
mov al 10001101B;
CBW al ; ax = 11111111 10001101B
mov ax 12H;
CBW ax ; eax = FF12H用汇编实现+-*/int add_asm(int x,int y)
{
__asm
{
mov eax,x
mov ebx,y
add eax,ebx //函数返回值是放在eax中的
}
}
int sub_asm(int x,int y)
{
__asm
{
mov eax,x
sub eax,y //函数返回值是放在eax中的
}
}
int imul_asm(int x,int y)
{
__asm
{
mov eax,x
mov ebx,y
imul ebx //函数返回值是放在eax中的,edx的值怎么返回?假设不会结果不会超过4Byte,
//如果超过4Byte,在函数中定义多一个,传入参数的指针,edx部分可以存放在指针指向的变量来返回
}
}
int idiv_asm(int x,int y,int *r)
{
__asm
{
xor edx,0
mov eax,x
idiv y //(edx:eax)/y-->q-->eax,r-->edx
mov ebx,r
mov [ebx],edx //r
}
}
逻辑指令逻辑(位)运算AND(and) 与OR(or) 或NOT(not) 取反XOR(exclusive or) 异或and eax,1 ;eax = eax&1
or eax,1 ;eax = eax|1
not eax ;eax = ~eax
xor eax,eax ;eax= eax^eax
xor eax,ebx ;eax = eax^ebxTEST(test) 测试:(DST)&(SRC) test两个操作数相与的结果不保存,只根据其特征置条件码(影响EFLAGS寄存器ZF位,配合jz/jnz等条件跳转指令)Mov eax,2
Test eax,1 ;10&01=0
jz L1
L1:
xor eax,eax
L2:
mov eax,1移位运算SHL(shift logical left) 逻辑左移SAL(shift arithmetic left) 算术左移,与shl一样SHR(shift logical right) 逻辑右移SAR(shift arithmetic right) 算术右移ROL(Rotate left) 循环左移ROR(Rotate right) 循环右移RCL(Rotate left through carry) 带进位循环左移RCR(Rotate right through carry) 带进位循环右移;格式: SHL OPR,CNT(其余的类似)
;其中OPR可以是除立即数以外的任何寻址方式。移位次数由CNT决定,CNT需要放在CL(CX寄存器的低8位)寄存器中
mov al 00110011B
mov cl,3
shl al cl ; al = 11001100B 逻辑左移
sal al cl ; al = 11001100B 算术左移(C语言中对应的左移)
shr al cl; al = 00001100B 逻辑右移(左边用0填充)
sar al cl ; al = 11001100B 算术右移(左边用符号位填充)(C语言中对应的右移)
shr al cl ; al = 10011001B 循环左移
shr al cl ; al = 01100110B 循环右移
mov cl,1
clc ; CF = 0
mov al,88h ; CF,AL = 0 10001000b
rcl al,cl ; CF,AL = 1 00010000b
rcl a1,cl ; CF,AL = 0 00100001b
;rcr 同理用汇编实现算术左/右移/// xy
int sar_asm(int x,int y)
{
__asm
{
mov eax,x
mov cl,byte ptr y //不会超过127的,目前还没有128位系统比不通用
sar eax,cl
}
}
串操作指令movsMOVS BYTE PTR[DI],BYTE PTR[SI](双字) MOVSB(字节)MOVSW(字)执行的操作: 1.((DI))空:栈顶指针指向下一个入栈的有效数据项,递减:栈往低地址生长,栈的增长方向和内存的增长方向相反入栈时:先存数据,栈顶指针再减;出栈时:栈顶指针先加,再取数据;push eax
//等价于:
mov [esp],eax
sub esp 4
pop eax
//等价于
add esp,4
mov eax,[esp]
满递增栈(FA) 满:栈顶指针指向最后一个入栈的有效数据项,递增:栈往高地址生长,栈的增长方向和内存的增长方向相同入栈时:栈顶指针先加,再存数据;出栈时:先取数据,栈顶指针再减;push eax
//等价于:
add esp 4
mov [esp],eax
pop eax
//等价于
mov eax,[esp]
sub esp,4
空递增栈(EA) 满:栈顶指针指向最后一个入栈的有效数据项,递增:栈往高地址生长,栈的增长方向和内存的增长方向相同入栈时:栈顶指针先加,再存数据;出栈时:先取数据,栈顶指针再减;push eax
//等价于:
add esp 4
mov [esp],eax
pop eax
//等价于
mov eax,[esp]
sub esp,4
空递增栈(EA) 满:栈顶指针指向下一个入栈的有效数据项,递增:栈往高地址生长,栈的增长方向和内存的增长方向相同入栈时:先存数据,栈顶指针再加;出栈时:栈顶指针先减,再取数据;push eax
//等价于:
mov [esp],eax
add esp 4
pop eax
//等价于
sub esp,4
mov eax,[esp]
X86系统中函数调约定cdecl: 参数从右往左依次入栈,栈对齐调用者栈平衡(程序员自己负责栈平衡)变参函数(比如printf)必须要使用cdecl调用约定,因为被调用者是不知道函数的参数的个数的,只有调用者才知道,必须要调用者自己负责栈平衡。stdcall 参数从右往左依次入栈(栈对齐)被调用者栈平衡(函数本身)驱动中使用的是stdcallfastcall 前两个参数放入ecx,edx,后面参数从右往左依次入栈(栈对齐),比如函数有5个参数,后面的第3,4,5参数从右往左依次入栈,第2参数放入edx,第1参数放入ecx。被调用者栈平衡在x64采用的都是fastcall,而且增加了r8,r9寄存器/**
* 函数参数右往左次入栈,栈对齐,参数大小会提升到4个字节,比如char,short 1Byte/2Byte数据存放在4Byte的空间中
* 在printf中float会提升到double(4Byte->8Byte)
*
* 低 --------- 汇编指令格式详解为什么mov有不同的指令形式?能不能自己诫算这个机器码? 满:栈顶指针指向下一个入栈的有效数据项,递增:栈往高地址生长,栈的增长方向和内存的增长方向相同入栈时:先存数据,栈顶指针再加;出栈时:栈顶指针先减,再取数据;push eax
//等价于:
mov [esp],eax
add esp 4
pop eax
//等价于
sub esp,4
mov eax,[esp]
X86系统中函数调约定cdecl: 参数从右往左依次入栈,栈对齐调用者栈平衡(程序员自己负责栈平衡)变参函数(比如printf)必须要使用cdecl调用约定,因为被调用者是不知道函数的参数的个数的,只有调用者才知道,必须要调用者自己负责栈平衡。stdcall 参数从右往左依次入栈(栈对齐)被调用者栈平衡(函数本身)驱动中使用的是stdcallfastcall 前两个参数放入ecx,edx,后面参数从右往左依次入栈(栈对齐),比如函数有5个参数,后面的第3,4,5参数从右往左依次入栈,第2参数放入edx,第1参数放入ecx。被调用者栈平衡在x64采用的都是fastcall,而且增加了r8,r9寄存器/**
* 函数参数右往左次入栈,栈对齐,参数大小会提升到4个字节,比如char,short 1Byte/2Byte数据存放在4Byte的空间中
* 在printf中float会提升到double(4Byte->8Byte)
*
* 低 --------- 汇编指令格式详解为什么mov有不同的指令形式?能不能自己诫算这个机器码?  参考学习: 参考学习:  可以用__asm{想要验证的汇编指令}在程序调试进行验证汇编指令格式通用寄存器X86:8个通用寄存器,X64:16个通用寄存器 -eax,ebx,ecx,edx,esi,edi,esp,ebp(e表示extend) rax,rbx,rcx,rdx,rsi,rdi,rsp,rbp(re表示re extend) r8,r9,r10,r11,r12,r13,r14,r15(新增寄存器)对通用寄存器编号,寄存器不同,指令不同 可以用__asm{想要验证的汇编指令}在程序调试进行验证汇编指令格式通用寄存器X86:8个通用寄存器,X64:16个通用寄存器 -eax,ebx,ecx,edx,esi,edi,esp,ebp(e表示extend) rax,rbx,rcx,rdx,rsi,rdi,rsp,rbp(re表示re extend) r8,r9,r10,r11,r12,r13,r14,r15(新增寄存器)对通用寄存器编号,寄存器不同,指令不同  x86用3bit表示,x64需要用4bit表示操作码每条指令都有一个或多个编码 x86用3bit表示,x64需要用4bit表示操作码每条指令都有一个或多个编码  7种寻址方式:寻址方式不同指令不同,比如mov指令,不同寻址方式,mov的指令也不一样立即数寻址: mov al,44h寄存器寻址: mov ds,ax直接寻址方式:mov al,DS: [2000h]寄存器间接寻址方式:mov ax,[bx]寄存器相对寻址方式:mov ax,[ebp + 1000]基址变址寻址方式:mov ax,[bx + si]相对基址变址寻址方式:mov ax,[bx +si*n + 1000];n=1,2,4,8X86汇编指令格式 7种寻址方式:寻址方式不同指令不同,比如mov指令,不同寻址方式,mov的指令也不一样立即数寻址: mov al,44h寄存器寻址: mov ds,ax直接寻址方式:mov al,DS: [2000h]寄存器间接寻址方式:mov ax,[bx]寄存器相对寻址方式:mov ax,[ebp + 1000]基址变址寻址方式:mov ax,[bx + si]相对基址变址寻址方式:mov ax,[bx +si*n + 1000];n=1,2,4,8X86汇编指令格式 字段(变长,1到17个字节(4+3+1+1+4+4)):refix : 可以有,可以没有,最多可以有四个。比如rep movs byte ptr[edi],byte ptr[esi]Opcode:1,2,3Byte,唯一必须的字段,其它都是optional的ModR/M:一个字节 Mod:占两位,00寄存器间接寻址,01寄存器相对寻址偏移8位。10寄存器相对寻址偏移32位,11寄存器直接寻址。Reg/Opcode:Reg/Opcode有时候是opcode的补充操作码。有时候是第个操作数寄存器(由指令定义决定) R/M:RM占3位,指定寄存器编号其中中Mod和RM定义了32种寻址方式SIB:ModRM的补充寻址方式基址变址寻址 eg:相对基址变址寻址[ebp+ebx*2+10h],Scale倍率00表示*1,01表示*2,10表示*4,11表示*8index:倍率寄存器编号Bese基址寄存器编号Dis:偏移,1个,2个或者4个字节;IMM: 立即数,1,2,4个字节eg:手工根据汇编指令计算出机器码//计算流程:Opcode 'mod reg/opcode r/m' 'ss index base' disp imm
// mov r/m32 imm32 对应的机器码是C7 /0(reg/opcode)
// 寻址方式是寄存器相对寻址偏移8位 对应Mod:01
// reg/opcode是000
// ebp编号是101
// C7 45
// `SIB`字段没有
// disp是-38h,即C8
// imm32是1,低位优先,即01 00 00 00
// 合起来就是C7 45 C8 01 00 00 00
mov dword ptr [ebp-38h],1 //C7 45 C8 01 00 00 00
mov [ebp-38h],eax //89 45 c8
mov
dword ptr [ebp+ebx-38b],0 //C7 84 1D C8 FF FF FF 00 00 00 00
mov ebx,eax //8B D8
ADD DWORD PTR DS[ESI+ECX*4],EAX //SiB:8Eh
X64汇编指令格式 字段(变长,1到17个字节(4+3+1+1+4+4)):refix : 可以有,可以没有,最多可以有四个。比如rep movs byte ptr[edi],byte ptr[esi]Opcode:1,2,3Byte,唯一必须的字段,其它都是optional的ModR/M:一个字节 Mod:占两位,00寄存器间接寻址,01寄存器相对寻址偏移8位。10寄存器相对寻址偏移32位,11寄存器直接寻址。Reg/Opcode:Reg/Opcode有时候是opcode的补充操作码。有时候是第个操作数寄存器(由指令定义决定) R/M:RM占3位,指定寄存器编号其中中Mod和RM定义了32种寻址方式SIB:ModRM的补充寻址方式基址变址寻址 eg:相对基址变址寻址[ebp+ebx*2+10h],Scale倍率00表示*1,01表示*2,10表示*4,11表示*8index:倍率寄存器编号Bese基址寄存器编号Dis:偏移,1个,2个或者4个字节;IMM: 立即数,1,2,4个字节eg:手工根据汇编指令计算出机器码//计算流程:Opcode 'mod reg/opcode r/m' 'ss index base' disp imm
// mov r/m32 imm32 对应的机器码是C7 /0(reg/opcode)
// 寻址方式是寄存器相对寻址偏移8位 对应Mod:01
// reg/opcode是000
// ebp编号是101
// C7 45
// `SIB`字段没有
// disp是-38h,即C8
// imm32是1,低位优先,即01 00 00 00
// 合起来就是C7 45 C8 01 00 00 00
mov dword ptr [ebp-38h],1 //C7 45 C8 01 00 00 00
mov [ebp-38h],eax //89 45 c8
mov
dword ptr [ebp+ebx-38b],0 //C7 84 1D C8 FF FF FF 00 00 00 00
mov ebx,eax //8B D8
ADD DWORD PTR DS[ESI+ECX*4],EAX //SiB:8Eh
X64汇编指令格式@todo x64暂时先放一放 x64汇编x64汇编不能像x86汇编那样嵌入到C语言代码中,而是需要把汇编独立写在一个.asm文件中。@todo 待完善,x64很少遇到,暂时先放一放什么是逆向(静态)分析?正向开发: C源程序(.c/.cpp)->汇编程序(.S) ->二进制(.exe/.dll/.sys或者.elf/.so)->加壳保护逆向开发: C源程序(.c/.cpp)顺序流指令:线性扫描;条件指令:将真的目标地址放入到延迟地址列表(延迟反汇编),为假分支继续线性反汇编。无条件跳转指令:直接把目标地址放入延迟地址列表,问题:jmp eax;(寄存器的值只有在程序运行的时候才能知道,IDA进行静态反汇编,拿不到值的)函数调用:将目标地址放入到延迟地址列表(call eax问题), 返回后线性扫描后续指令(如果返回地址被窜改,会有问题,ret指令:反汇编终止(因为函数在栈上,只能在运行的时候才能确定,静态分析ret的位置无法确定,)),从延迟地址列表里取一个地址继续反汇编。能够区分代码和数据,无法识别通过代码指针表来进行的间接跳转(switch语句)(启发式方法解决)Windbg,objdump采用线性扫描;IDA PRO使用的递归下降法反汇编启动与关闭IDAIDA的启动32位与64位 32位程序提供汇编转C语言伪代码功能(F5)64位程序提供64位汇编解析功能,64位程序无法将汇编转C语言伪代码NEW打开动态库、ex静态库、中间文件、apk等等二进制文件NEW->选择需要逆向程序->默认选项(文件加载器,处理器类型)->在分析的过程中可能会提示带符号(只有调试自己的程序才有符号提示,选择加载符号,可读性更佳,如果错过了,还有另一次加载符号的机会File-Load file-PDB file)生成数据库文件(存放在目标逆向文件的同一路径下) .id0二叉树形式的数据.nam符号.til分析到的一些数据类型以上数据合起来称为数据库(退出IDA后,默认会打包成一个.idb文件)GO用于调试正在运行的程序,或者暂时没有想好的情况直接进入IDA,没有任何内容,需要手动Load要分析的文件进来Previous加载上次文件 继续上次的逆向工作IDA的基本功能打开加壳的文件加了upx壳的文件 函数名称和导入表都无法解析出来解决方法:先脱壳,再用IDA进行分析如何获取被删除的.sys文件有些程序在释放出驱动,加载驱动之后会把驱动文件删除,避免被分析。思路: HIPS拦截(文件过滤驱动),最方便,最准确 HIPS拦截(文件过滤驱动),最方便,最准确 内存拷贝PE资源编辑器(PE Edit/PE Explorer,程序释放出驱动,说明驱动存放在程序中,即PE文件的资源节里面)IDA的关闭不需要保存:勾选DON’ T SAVE the database需要保存 内存拷贝PE资源编辑器(PE Edit/PE Explorer,程序释放出驱动,说明驱动存放在程序中,即PE文件的资源节里面)IDA的关闭不需要保存:勾选DON’ T SAVE the database需要保存 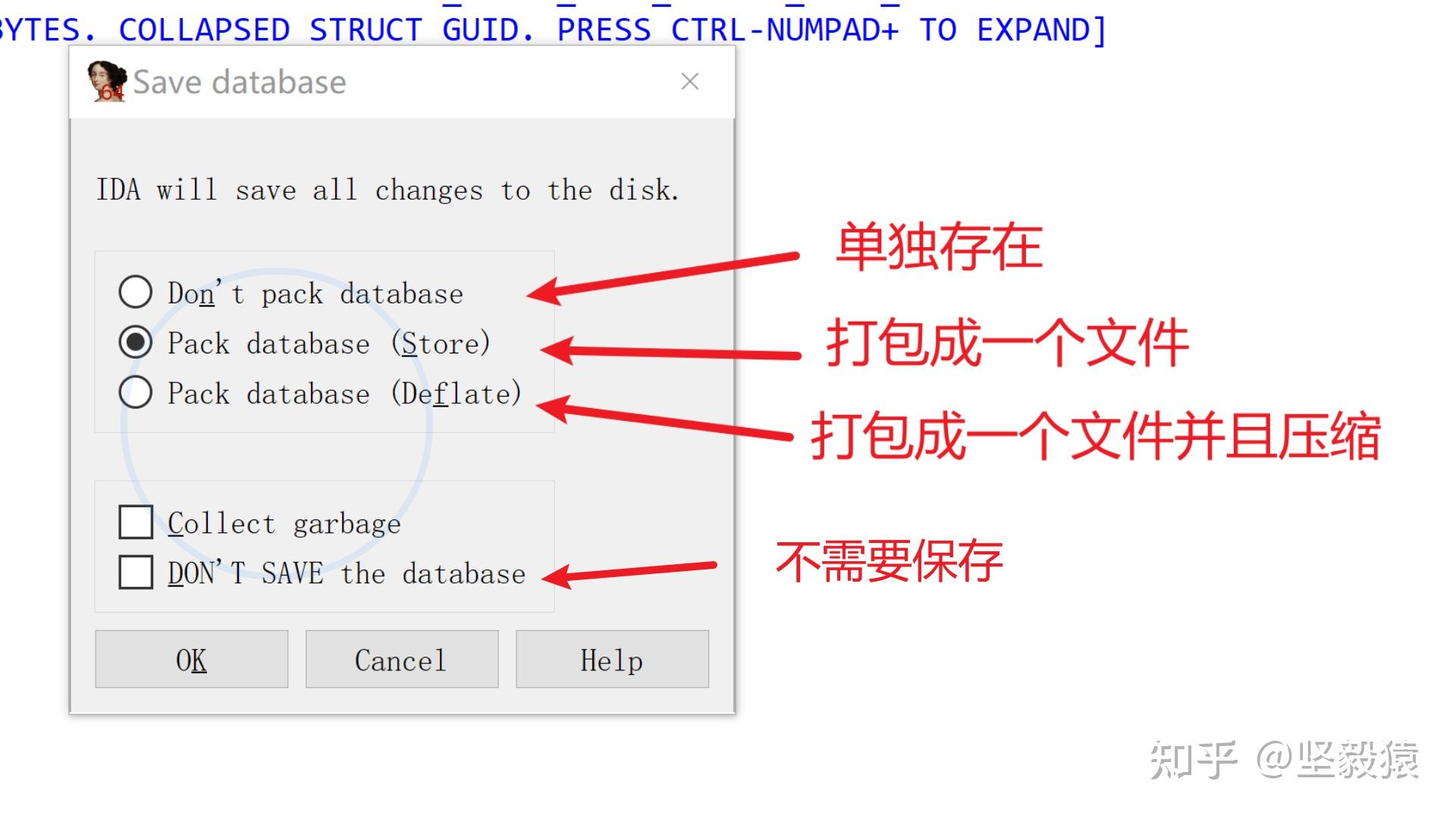 常见问题找不到模块 只影响脚本,不影响ida反汇编功能可能是没有设置好python的环境路径,或者因为ida的python版本是2.0和安装的python3.0冲突IDA视窗与窗口汇编视图“汇编视图(IDA View)“是IDAPro静态分析程序的最主要的界面,该界面显示了各个函数的汇编代码。汇编视图提供了2种形式的显示方法,一种是基于文本的显示,另1种是基于 图形的显示,二者之间可以通过空格键进行快速的切换。默认显示图形还是文本可以通过选项设置在汇编视图里,既可能遇到代码指 令也可能会遇到数据。在分析的时候,它们之间可以用命令进行相互转化和重命 可以将光标放在对应的数据行,然后通过多次按下D捷键来改变该数据的类型(最常见的是从db/dw/dd之间切换)也可以按下C键来将对应的数据转化为代码指令;对于代码指令通过按键U来转化为数据;而对于函数名,变量名以及寄存器,可以通过N按键来修改名字,以提高代码的可读性。函数窗口 常见问题找不到模块 只影响脚本,不影响ida反汇编功能可能是没有设置好python的环境路径,或者因为ida的python版本是2.0和安装的python3.0冲突IDA视窗与窗口汇编视图“汇编视图(IDA View)“是IDAPro静态分析程序的最主要的界面,该界面显示了各个函数的汇编代码。汇编视图提供了2种形式的显示方法,一种是基于文本的显示,另1种是基于 图形的显示,二者之间可以通过空格键进行快速的切换。默认显示图形还是文本可以通过选项设置在汇编视图里,既可能遇到代码指 令也可能会遇到数据。在分析的时候,它们之间可以用命令进行相互转化和重命 可以将光标放在对应的数据行,然后通过多次按下D捷键来改变该数据的类型(最常见的是从db/dw/dd之间切换)也可以按下C键来将对应的数据转化为代码指令;对于代码指令通过按键U来转化为数据;而对于函数名,变量名以及寄存器,可以通过N按键来修改名字,以提高代码的可读性。函数窗口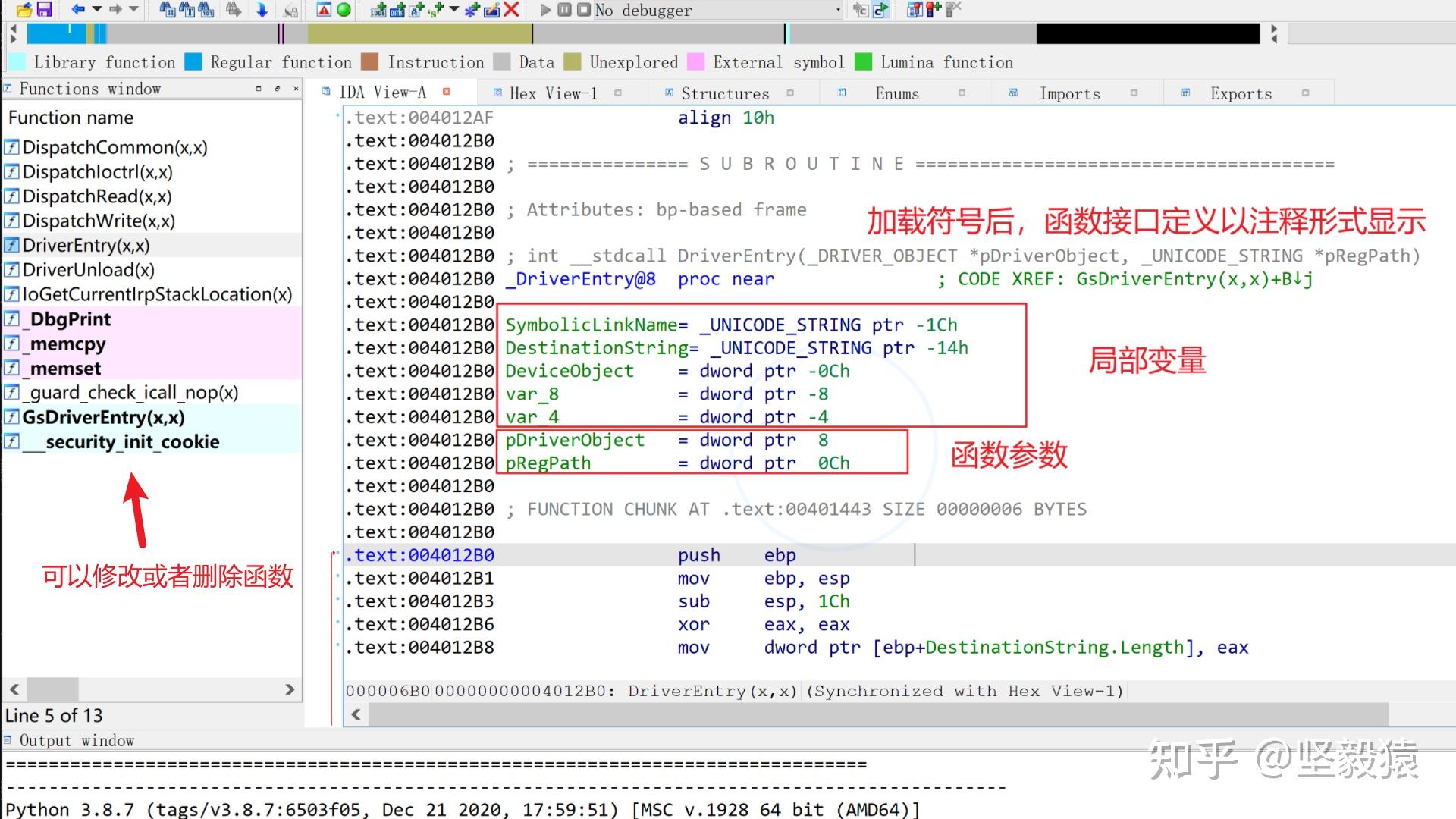 “函数窗口”列出了所有模块中存在的函数,双击任意函数,就可以定位到该函数的实际位置。 如果加载符号,函数的返回类型,调用约定,函数名称,函数的参数列表,参数类型以注释的形式提供。如果未加载符号,那么函数名可能以sub_location的形式存在。如果函数解析不准确,可以修改或者删除 “函数窗口”列出了所有模块中存在的函数,双击任意函数,就可以定位到该函数的实际位置。 如果加载符号,函数的返回类型,调用约定,函数名称,函数的参数列表,参数类型以注释的形式提供。如果未加载符号,那么函数名可能以sub_location的形式存在。如果函数解析不准确,可以修改或者删除 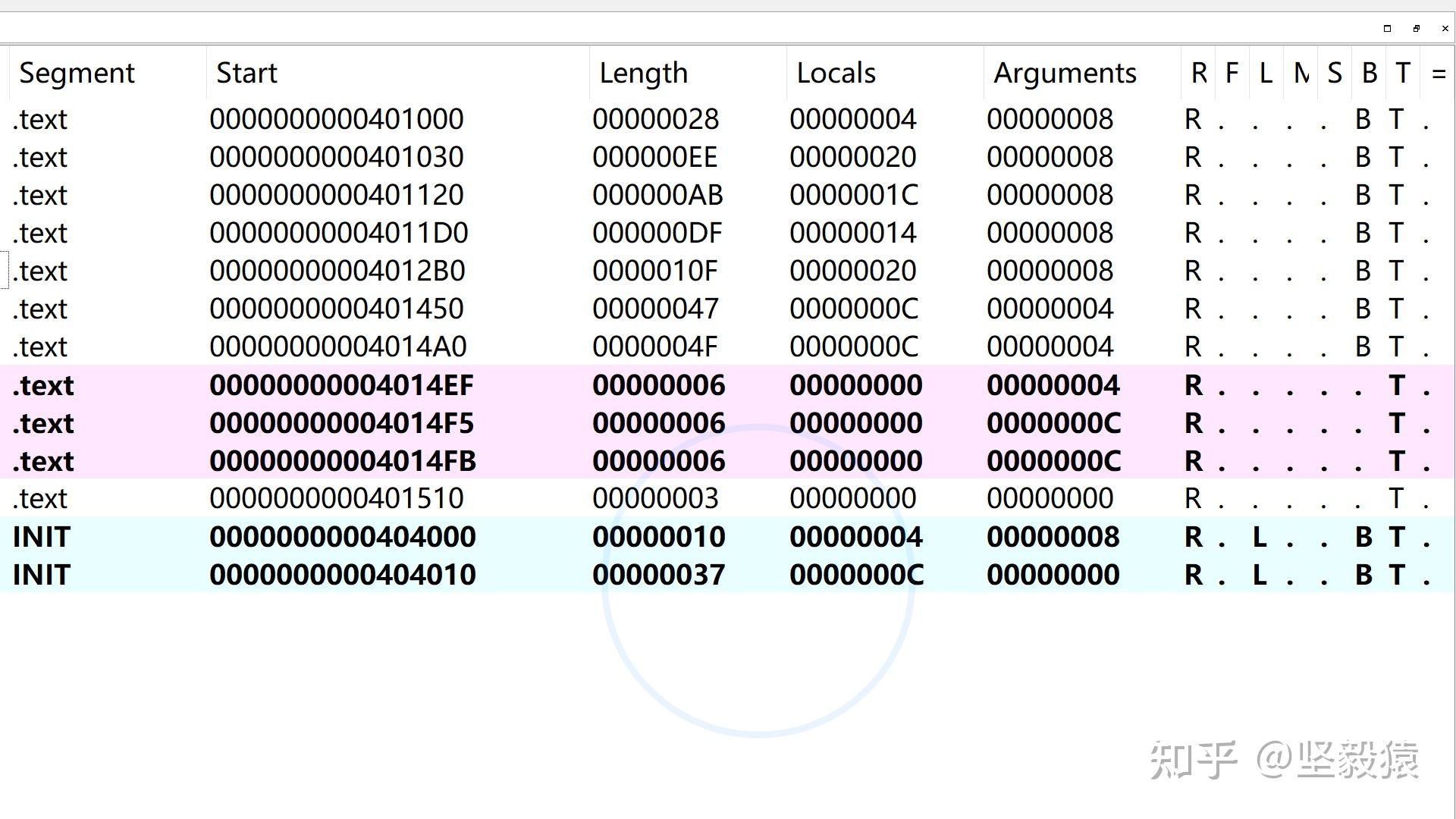 R:返回给调用者F:far functionL:库函数S:static functionB:用ebp+来访问形参,ebp-来访问局部变量T:函数拥有类型信息=:栈帧的指针指向的是栈帧的基地址名字窗口“名字窗口"列出了IDA分析出的所有全局的名字。这些名字就是对虚拟内存地址的一个符号描述(比如变量函数名等)。鼠标双击这些名字就会快速跳到对应的汇编窗口对应的位置。名字前面的字符表示了不同的名字类别: F:普通函数L:库函数I:导入函数的名字,无代码部分(现在是个箭头,I表示标号位置)C:命名代代码。不属于任何函数D:命名数据,比如全局变量A:ASCII字符串,大于4个字符字符串窗口“字符串窗口"列出了IDA识别出来的所有字符串该字符串窗口对于分析程序的关键点非常有用。因为过主一般都具有意义作可以猜测引用该字符串位置的代码的作用。尤其是那些进行安全验证的地方可以遇字符串进行快速定位。双击某个字符串,就可以快速定位到字符串定义和引用的位置。或者也可以通过"ALT+T"快捷键来查找字符串的引用位置。窗口右键setup配置 R:返回给调用者F:far functionL:库函数S:static functionB:用ebp+来访问形参,ebp-来访问局部变量T:函数拥有类型信息=:栈帧的指针指向的是栈帧的基地址名字窗口“名字窗口"列出了IDA分析出的所有全局的名字。这些名字就是对虚拟内存地址的一个符号描述(比如变量函数名等)。鼠标双击这些名字就会快速跳到对应的汇编窗口对应的位置。名字前面的字符表示了不同的名字类别: F:普通函数L:库函数I:导入函数的名字,无代码部分(现在是个箭头,I表示标号位置)C:命名代代码。不属于任何函数D:命名数据,比如全局变量A:ASCII字符串,大于4个字符字符串窗口“字符串窗口"列出了IDA识别出来的所有字符串该字符串窗口对于分析程序的关键点非常有用。因为过主一般都具有意义作可以猜测引用该字符串位置的代码的作用。尤其是那些进行安全验证的地方可以遇字符串进行快速定位。双击某个字符串,就可以快速定位到字符串定义和引用的位置。或者也可以通过"ALT+T"快捷键来查找字符串的引用位置。窗口右键setup配置  PE区段窗口View-open subviews-segmention或者CTRL+S快捷键"PE区段窗口“列出了分析文件的所有PE区块: HEADER:PE头.text:代码段.idata:导入表所在数据段.rdata:只读数据段.data:数据段INIT:初始化段.reloc:存放基地址重定向表的重定向节,用于当irmageBase改变后,对映像内的使用的地址进行重定位。用鼠标双击这些区段,就可以直接跳到对应的汇编代码或者数据位置。导入/出表窗口 PE区段窗口View-open subviews-segmention或者CTRL+S快捷键"PE区段窗口“列出了分析文件的所有PE区块: HEADER:PE头.text:代码段.idata:导入表所在数据段.rdata:只读数据段.data:数据段INIT:初始化段.reloc:存放基地址重定向表的重定向节,用于当irmageBase改变后,对映像内的使用的地址进行重定位。用鼠标双击这些区段,就可以直接跳到对应的汇编代码或者数据位置。导入/出表窗口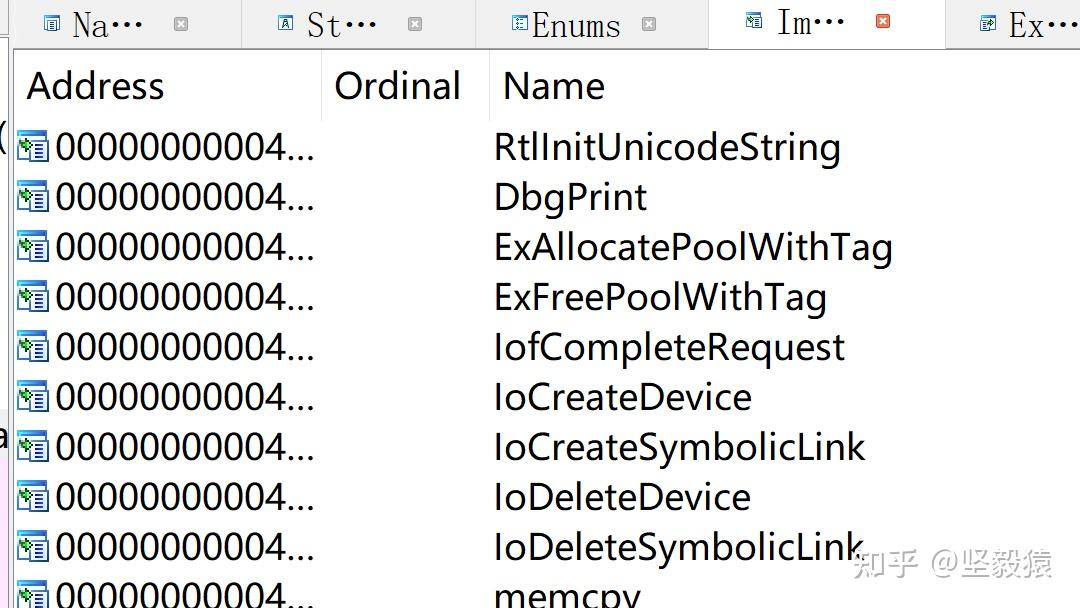 导入表(导入那些库函数,可以从侧面分析程序的功能)导出表(驱动时DriverEntry,应用程序则是Main)其他窗口输出窗口(ida分析过程中的信息、或者脚本运行的结果)程序内存布局彩条IDA基本操作查找文本查找 ATL+T/CTRL+T以Byte为单位查找二进制值 ATL+B/CTRL+T跳转双击就可以直接跳转CTRL+S可以跳转到某个节CTRL+E可以跳转到入口点G可以跳转到指定目的地址CTRL+L按照名字跳转编辑编辑修改都是为了提高代码可读性,使得分析的时候更加清晰 1.重命名,快捷键N 2.代码与数据转换:C,U,D,A 3.注释: 普通注释:可重复注释;如果一个程序位置引用了另外一个包含可重复注释的位置,则该注释会在第一个位置回显。) 4.修改数组:Edit-Array 5.修改函数栈指针(stdcall) EDIT->Functions->Change Stack Pointer(ALT+K) 导入表(导入那些库函数,可以从侧面分析程序的功能)导出表(驱动时DriverEntry,应用程序则是Main)其他窗口输出窗口(ida分析过程中的信息、或者脚本运行的结果)程序内存布局彩条IDA基本操作查找文本查找 ATL+T/CTRL+T以Byte为单位查找二进制值 ATL+B/CTRL+T跳转双击就可以直接跳转CTRL+S可以跳转到某个节CTRL+E可以跳转到入口点G可以跳转到指定目的地址CTRL+L按照名字跳转编辑编辑修改都是为了提高代码可读性,使得分析的时候更加清晰 1.重命名,快捷键N 2.代码与数据转换:C,U,D,A 3.注释: 普通注释:可重复注释;如果一个程序位置引用了另外一个包含可重复注释的位置,则该注释会在第一个位置回显。) 4.修改数组:Edit-Array 5.修改函数栈指针(stdcall) EDIT->Functions->Change Stack Pointer(ALT+K)  IDA PATCH 花指令方法用nop替换花指令 Edit-Patch program-Change byte或者点右键-Keypatch-Patcher查看 Patch的历史 Patched bytes应用到文件中 Apply patches to input file数据、代码交叉引用int read_id;
int write_id;
int ref_id;
void callfunc()
{
printf ("callfunc\n");
}
int _trmain(int argc,_TCHAR* argv[])
{
int *p = &ref_id; //地址引用
*p = read_id; //读引用
write_id = *p; //写引用
callfunc();
if(read_id==5)
write_id = 2;
else
write_id = 1;
callfunc();
return 0;
} IDA PATCH 花指令方法用nop替换花指令 Edit-Patch program-Change byte或者点右键-Keypatch-Patcher查看 Patch的历史 Patched bytes应用到文件中 Apply patches to input file数据、代码交叉引用int read_id;
int write_id;
int ref_id;
void callfunc()
{
printf ("callfunc\n");
}
int _trmain(int argc,_TCHAR* argv[])
{
int *p = &ref_id; //地址引用
*p = read_id; //读引用
write_id = *p; //写引用
callfunc();
if(read_id==5)
write_id = 2;
else
write_id = 1;
callfunc();
return 0;
}
 数据引用 View->Open Subview->Cross references或X(列举所有交叉引用当前符号的地方,比如strcpy,容易造成缓存区溢出的漏洞,可以找到所有调用的地方strcpy,更好利用漏洞)o:地址应用r:读引用w:写引用代码引用 View->Open Subviews->Function calls(列举所有应用该函数的地方和该函数调用的函数) 数据引用 View->Open Subview->Cross references或X(列举所有交叉引用当前符号的地方,比如strcpy,容易造成缓存区溢出的漏洞,可以找到所有调用的地方strcpy,更好利用漏洞)o:地址应用r:读引用w:写引用代码引用 View->Open Subviews->Function calls(列举所有应用该函数的地方和该函数调用的函数)  p:函数引用j:跳转引用反C插件Hex-rays将光标定位到该函数内部本后直接按下快捷键F5,那么,整函数就会被直接翻译成对应的C代码64位的IDA没有安装反C插件Hex-rays,所以要看C代码需要使用32位的IDA。结构体结构体(structures)视图结构体视图显示IDA决定在一个二进制文件中使用的任何复杂的数据结构布局。列举出了IDA在分析过程中识别出来的结构体信息,而那些IDA自己未成功识别的结构体,也可以通过IDA提供的方式来添加。数组的某个元素或者结构体的某个成员在汇编代码中的特征并不明显。所以需要手动把人工识别的结构体放在结构体视图中,只有在该视图里出现的结构体才可以被整合到IDA的汇编视图里,提高代码的可读性(用结构体成员访问去重命名汇编代码中的偏移)。添加IDA未成功识别的结构体方式1: Insert快捷键添加 在该视图里,通过Insert快捷键添加,在弹出的对话框里指定结构体的名字,或者直接从对话框不面的按钮"Add standard structure"中选择标准库中的结构体。在对话框中点击OK按钮之后,刚才定义的结构体名字将会在视图中出现。这个时候,将光标移动到结构体定义的最后行,按D键,可以往结构体里插入成员,再按D,可以切换成员的类型。按A键,可以往结构体里插入数组成员删除结构体中间的成员:U→开始菜单Edit->Shrink struct type在结构体中间增加一个成员: Edit->Expand struct type在结构体中删除最后一个成员: 将光标移动到结构体ENDS一行,按U键重命名一个结构体成员:将光称移到该成员,按N键即可重命名。效率低方式2:通过Local Types添加 通过Local Types添加这种方式可以通过菜单View→OpenSubviews Local Types→INSERT插入种个用C结构体方式定义的结构体。这种方式比第一种方式更容易和方便。通过这种方式新插入的结构体不会直接插入structures视图而是放在了标准库中,因此必须通过第一种方式中的insert快捷键,然后选择从对话框下面的按钮Add standard structure中选择标准库中的结构体来加入结构体视图中。也可以通过在Local Type视图里双击该结构体,将它加入到Structures视图中。方式3:通过头文件添加 lDA Pro支持直接从头文件中添加结构体。添加方法是从菜单FILE->LOAD FILE->Parse C headler file就可以将头文件中的结构体导入。与第2种方法类似,通过头文件添加的结构体也被导入到称准库中的后面,也需要通过第种方式中的insert快捷键,然后选择从对话框下面的按钮Add standard structure 中选择标准库中的刚插入的结构体加入到结构体视图中。在汇编代码中运用结构体可以往结构体视图加入IDA未识别的结构体。加完自己定义的结构体之后,就可以在汇编代码中运用结构体。对于普通代码,将光标移动到汇编代码中存器+偏移的位置,然后右键,在弹出的菜单中,选择Struct offset就会将结构体视图中与这个偏移匹配的结构体成员引入。这样汇编代码就由[eax+4h]变为了[eax+mystrucmber]而对于栈的变量(结构体汇编代码特征不明显,每个成员都会被IDA识别成一个独立的变量),如里想运用相应的结构体类型,方法如下: 首先在函数内部栈空间上鼠标双击IDA会切换到函数的栈空间视图:这个时候,将光标移到对应的栈变量上,然后通过Edit→Struct Var(ALT+Q),选择要转换的结构体类型。还可以用N修改汇编代码中的结构体名,进一步增强可读性。IDA脚本编程IDA集成了2个脚本引擎(一个是IDC,一个是Python),让用户从编程角度对IDA的操作进行全面控制,从而自动执行常规任务。以编程方式访问和查询IDA数据库,分析整理数据,可用于脱壳,去模糊,自动化分析方面。免去了手工操作的繁琐、低效和不便。lDC,类似于C语言语法与编程凤格Hello world三种方式执行IDC或者Python代码窗口 File->Script command//IDC
Message("hello world");
//python 3.x
print("hello world")
文件 File->Script file/// hello.idc
#include
static main()
{
Message ("hello world");
}
#hello.py
import idc
def print_hello();
print "hellc world"
print_hello()
命令行 p:函数引用j:跳转引用反C插件Hex-rays将光标定位到该函数内部本后直接按下快捷键F5,那么,整函数就会被直接翻译成对应的C代码64位的IDA没有安装反C插件Hex-rays,所以要看C代码需要使用32位的IDA。结构体结构体(structures)视图结构体视图显示IDA决定在一个二进制文件中使用的任何复杂的数据结构布局。列举出了IDA在分析过程中识别出来的结构体信息,而那些IDA自己未成功识别的结构体,也可以通过IDA提供的方式来添加。数组的某个元素或者结构体的某个成员在汇编代码中的特征并不明显。所以需要手动把人工识别的结构体放在结构体视图中,只有在该视图里出现的结构体才可以被整合到IDA的汇编视图里,提高代码的可读性(用结构体成员访问去重命名汇编代码中的偏移)。添加IDA未成功识别的结构体方式1: Insert快捷键添加 在该视图里,通过Insert快捷键添加,在弹出的对话框里指定结构体的名字,或者直接从对话框不面的按钮"Add standard structure"中选择标准库中的结构体。在对话框中点击OK按钮之后,刚才定义的结构体名字将会在视图中出现。这个时候,将光标移动到结构体定义的最后行,按D键,可以往结构体里插入成员,再按D,可以切换成员的类型。按A键,可以往结构体里插入数组成员删除结构体中间的成员:U→开始菜单Edit->Shrink struct type在结构体中间增加一个成员: Edit->Expand struct type在结构体中删除最后一个成员: 将光标移动到结构体ENDS一行,按U键重命名一个结构体成员:将光称移到该成员,按N键即可重命名。效率低方式2:通过Local Types添加 通过Local Types添加这种方式可以通过菜单View→OpenSubviews Local Types→INSERT插入种个用C结构体方式定义的结构体。这种方式比第一种方式更容易和方便。通过这种方式新插入的结构体不会直接插入structures视图而是放在了标准库中,因此必须通过第一种方式中的insert快捷键,然后选择从对话框下面的按钮Add standard structure中选择标准库中的结构体来加入结构体视图中。也可以通过在Local Type视图里双击该结构体,将它加入到Structures视图中。方式3:通过头文件添加 lDA Pro支持直接从头文件中添加结构体。添加方法是从菜单FILE->LOAD FILE->Parse C headler file就可以将头文件中的结构体导入。与第2种方法类似,通过头文件添加的结构体也被导入到称准库中的后面,也需要通过第种方式中的insert快捷键,然后选择从对话框下面的按钮Add standard structure 中选择标准库中的刚插入的结构体加入到结构体视图中。在汇编代码中运用结构体可以往结构体视图加入IDA未识别的结构体。加完自己定义的结构体之后,就可以在汇编代码中运用结构体。对于普通代码,将光标移动到汇编代码中存器+偏移的位置,然后右键,在弹出的菜单中,选择Struct offset就会将结构体视图中与这个偏移匹配的结构体成员引入。这样汇编代码就由[eax+4h]变为了[eax+mystrucmber]而对于栈的变量(结构体汇编代码特征不明显,每个成员都会被IDA识别成一个独立的变量),如里想运用相应的结构体类型,方法如下: 首先在函数内部栈空间上鼠标双击IDA会切换到函数的栈空间视图:这个时候,将光标移到对应的栈变量上,然后通过Edit→Struct Var(ALT+Q),选择要转换的结构体类型。还可以用N修改汇编代码中的结构体名,进一步增强可读性。IDA脚本编程IDA集成了2个脚本引擎(一个是IDC,一个是Python),让用户从编程角度对IDA的操作进行全面控制,从而自动执行常规任务。以编程方式访问和查询IDA数据库,分析整理数据,可用于脱壳,去模糊,自动化分析方面。免去了手工操作的繁琐、低效和不便。lDC,类似于C语言语法与编程凤格Hello world三种方式执行IDC或者Python代码窗口 File->Script command//IDC
Message("hello world");
//python 3.x
print("hello world")
文件 File->Script file/// hello.idc
#include
static main()
{
Message ("hello world");
}
#hello.py
import idc
def print_hello();
print "hellc world"
print_hello()
命令行  单语句可以使用命令行,少量语句可以使用窗口,复杂的语句可以使用文件基础语法 @todo函数遍历@todo调用者遍历@todo交叉引用查找@todo发行版代码保护与反逆向方法Release编译优化一般拿到的程序都是release版本的与调试版的程序不同,发行版的程序做了很多的编译优化,其对应的汇编代码将会更加的难以理解,可阅读性也会更差一些且没有对应的PDB符号文件,如下图所示在没有符号文件的时候、IDA识别出来的函数名都是自动命名,可读性就变得很差。 单语句可以使用命令行,少量语句可以使用窗口,复杂的语句可以使用文件基础语法 @todo函数遍历@todo调用者遍历@todo交叉引用查找@todo发行版代码保护与反逆向方法Release编译优化一般拿到的程序都是release版本的与调试版的程序不同,发行版的程序做了很多的编译优化,其对应的汇编代码将会更加的难以理解,可阅读性也会更差一些且没有对应的PDB符号文件,如下图所示在没有符号文件的时候、IDA识别出来的函数名都是自动命名,可读性就变得很差。 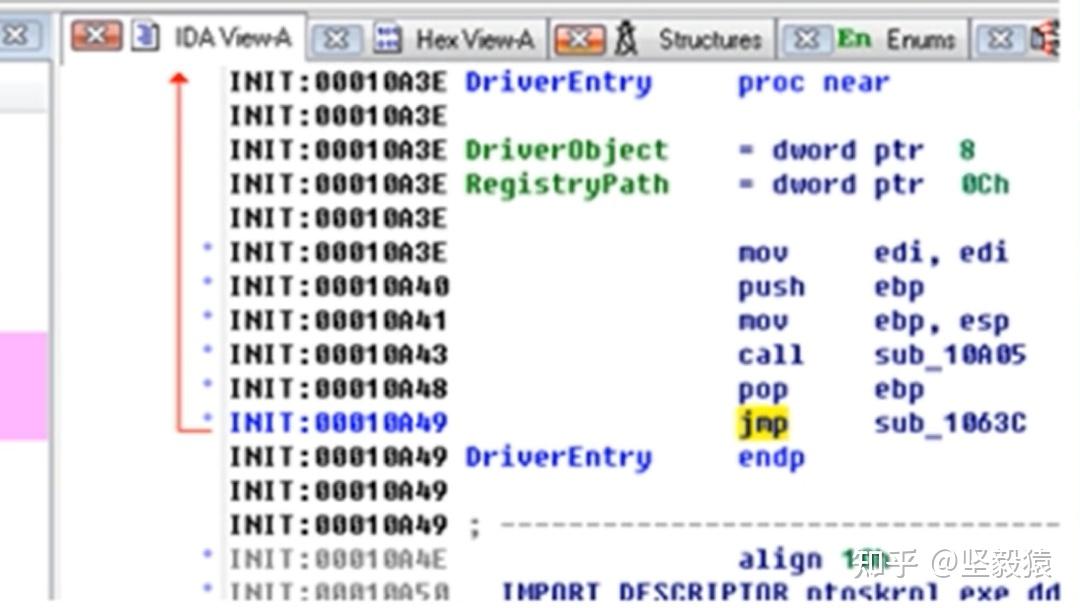 甚至是通过花指令或者OLLVM或者加壳混淆对抗IDA等工具。这样分析起来就会更加困难一些。反调试和反反调试反调试DebugProt 对于未导出的函数,无法通过符号来找到DebugProt,只能通过硬编码来找到DebugProt在内核层 KdDisableDebugger 在内核里调用KdDisableDebugger来禁用内核调试KdEnable Debugger 启用内核调试在应用层 开两个线程来分别调用IsDebugerPresent和CheckRemoteDebuggerPresent来检测自己是否被正在被调试,如果发现被调试,自己就退出,其他人就无法继续调试我了。/// 没有加入反调试代码的时候MFC程序是可以被windbg调试的,加入反调试代码之后,windbg调试MFC程序的是,MFC就会一闪而过退出
/// 反调试线程函数,放在MFC函数的执行入口
UINT AntiDebug(PVOIDparam)
{
while(g_bWillExit == FALSE)
{
HANDLE hRrocess = GetCurrentProcess();
BOOL bDebuggerPresent=FALSE;
CheckRemoteDebuggerPresent(hProces,&bDebuggerPresent);
if(IsDebuggerPresent()||bDebuggerPresent)
{
::ExitProce(0); //把当前进程结束掉
}
Sleep(5000); //每隔5s检测程序是否被调试
}
return 0;
}
AfxBeginThread((AFX_THREADPROC)AntiDebug, NULL); //启动反调试线程
Hook-Anti-debug hook系统中一些与调试相关的函数,以可以防止各种调试器调试。NTOpenThread() hook这个函数,可以防止调试器在程序内部创建线程NTOpenProcess() hook这个函数,可以防止OD(OllyDbg)等调试工具在进程列表中看到我们KiAttachProcess() hook这个函数,可以防止被附加上NtReadVirtualMemory() hook这个函数,可以防止被读内存NtWriteVirtualMemory() hook这个函数,可以防止被内存被写hook这两个函数用来防止双机调试 - KdReceivePacket() KDCOM.dll中Com串口接收数据函数 - KdSendPack() KDCOM.dll中Com串口发送数据函数反反调试ba w4 debugport 对DebugProt内存地址下断点 这样一旦有程序代码在修改DebugPort,就会被断下,从而找到对应清零DebugPort的反调试代码,然后对这部分代码进行patch(用机器码0x90(nop)或 者0xC3(ret)取代)从而让它失去作用,当然有的程序会对代码进行校验,一旦发现代码被篡改,就会采取保护措施,比如抛出异常或者退出程序。针对调用系统函数如KaDisabeDebugger()来检测调试器存在,从而禁止被调试的方法,可以在对应的这些函数的地址下断点,然后对相关的代码进行patch,然后使该函数判断失效。 比如bp KdDisableDebugger, eb xxx针对通过HOOK系统函数来防止进程被调试的方法,可以直接将 这些系统函数的钩子直接恢复,可以通过检测和恢复这些函数钩子。花指令 甚至是通过花指令或者OLLVM或者加壳混淆对抗IDA等工具。这样分析起来就会更加困难一些。反调试和反反调试反调试DebugProt 对于未导出的函数,无法通过符号来找到DebugProt,只能通过硬编码来找到DebugProt在内核层 KdDisableDebugger 在内核里调用KdDisableDebugger来禁用内核调试KdEnable Debugger 启用内核调试在应用层 开两个线程来分别调用IsDebugerPresent和CheckRemoteDebuggerPresent来检测自己是否被正在被调试,如果发现被调试,自己就退出,其他人就无法继续调试我了。/// 没有加入反调试代码的时候MFC程序是可以被windbg调试的,加入反调试代码之后,windbg调试MFC程序的是,MFC就会一闪而过退出
/// 反调试线程函数,放在MFC函数的执行入口
UINT AntiDebug(PVOIDparam)
{
while(g_bWillExit == FALSE)
{
HANDLE hRrocess = GetCurrentProcess();
BOOL bDebuggerPresent=FALSE;
CheckRemoteDebuggerPresent(hProces,&bDebuggerPresent);
if(IsDebuggerPresent()||bDebuggerPresent)
{
::ExitProce(0); //把当前进程结束掉
}
Sleep(5000); //每隔5s检测程序是否被调试
}
return 0;
}
AfxBeginThread((AFX_THREADPROC)AntiDebug, NULL); //启动反调试线程
Hook-Anti-debug hook系统中一些与调试相关的函数,以可以防止各种调试器调试。NTOpenThread() hook这个函数,可以防止调试器在程序内部创建线程NTOpenProcess() hook这个函数,可以防止OD(OllyDbg)等调试工具在进程列表中看到我们KiAttachProcess() hook这个函数,可以防止被附加上NtReadVirtualMemory() hook这个函数,可以防止被读内存NtWriteVirtualMemory() hook这个函数,可以防止被内存被写hook这两个函数用来防止双机调试 - KdReceivePacket() KDCOM.dll中Com串口接收数据函数 - KdSendPack() KDCOM.dll中Com串口发送数据函数反反调试ba w4 debugport 对DebugProt内存地址下断点 这样一旦有程序代码在修改DebugPort,就会被断下,从而找到对应清零DebugPort的反调试代码,然后对这部分代码进行patch(用机器码0x90(nop)或 者0xC3(ret)取代)从而让它失去作用,当然有的程序会对代码进行校验,一旦发现代码被篡改,就会采取保护措施,比如抛出异常或者退出程序。针对调用系统函数如KaDisabeDebugger()来检测调试器存在,从而禁止被调试的方法,可以在对应的这些函数的地址下断点,然后对相关的代码进行patch,然后使该函数判断失效。 比如bp KdDisableDebugger, eb xxx针对通过HOOK系统函数来防止进程被调试的方法,可以直接将 这些系统函数的钩子直接恢复,可以通过检测和恢复这些函数钩子。花指令花指令是程序中的无用指令或者垃圾指令,故意干扰各种反汇编静态分析工具,但是程序不受任何影响,缺少了它也能正常运行。加花指令后,IDA Pro等分析工具对程序静态反汇编时,往往会出现错误或者遭到破环,加大逆向静态分析的难度,从而隐藏自身的程序结构和算法从而较好的保护自己。 遇到花指令,需要手动udefine掉,很多的话需要写脚本剔除花指令、用插件模拟执行。花指令1 inc+dec//花指令1 //代码没有任何作用,但会混淆调试者 push edx pop edx inc ecx dec ecx add esp,1 sub esp,1 花指令2 jmp//花指令2 jmp Labe1 db opcode //在jmp后面加上一个字节的机器码,并不完整(完整的汇编指令是一个机器码+操作数),但不影响程序的执行(jmp会跳过这条残缺的汇编指令)。在IDE工具反汇编的时候,看到机器码(以为紧接着的就是操作数,接着后面的反汇编都错位了) Label1:但IDE采用的反汇编算法是递归如果没有指令跳转到这个位置,就拒绝对这条指令进行反汇编。 3. 花指令3 jz+jnz //花指令3 jz Label //花指令对代码依旧没有影响,为0的时候会跳过花指令。 jnz Label //非0才跳转到 Label,为0则执行下面的花指令,IDE此时就认为这条花指令需要反汇编。 db opcode //_emit 0e8h;call机器码 Label: emit伪指令,在当前位置直接插入数据(指令),一般用来插入汇编里面没有的特殊指令,和db,dw效果相同。目的:编译器不认识的指令,拆成机器码来写。花指令4 call+retcall一个地址,在call下面随便写入花指令并记住花指令字节长度在call里面,也就是函数里面姚首先pop出压入的地址,.然后把这个地址减去花指令占用的字节数(绕过花指令),再重新push进栈,然后就ret(跳到了花指苓的下一条指令)pop ebx //压栈地址弹出 inc ebx //压栈地址+1,绕过花指令 push ebx //返回地址完成加绕过了花指令 mov eax,0x1;设置返回值 ret - call 0A04B0D7迷惑了反汇编器,认为call之后会返回继续执行call的下一条指令,所以从0A04B0D6位置开始反汇编,实际上0A04B0D6位置放了一个Byte的垃圾值,call只是直接jmp 0A04B0D7,0A04B0D6不会被执行 - 解决方法:在0A04B0D6执行U命令,然后在0A04B0D7执行C命令把这条花指令patch掉  - jmp到自己的指令也有问题,必须去掉OA04BODB的定义(U快捷键),重新定义OA04BODC处的指令(C快捷键)。  - 最后执行的是jmp eax (是为了对抗静态反汇编,运行时才计算) 5. 花指令5 相对跳转指令构造绝对跳转 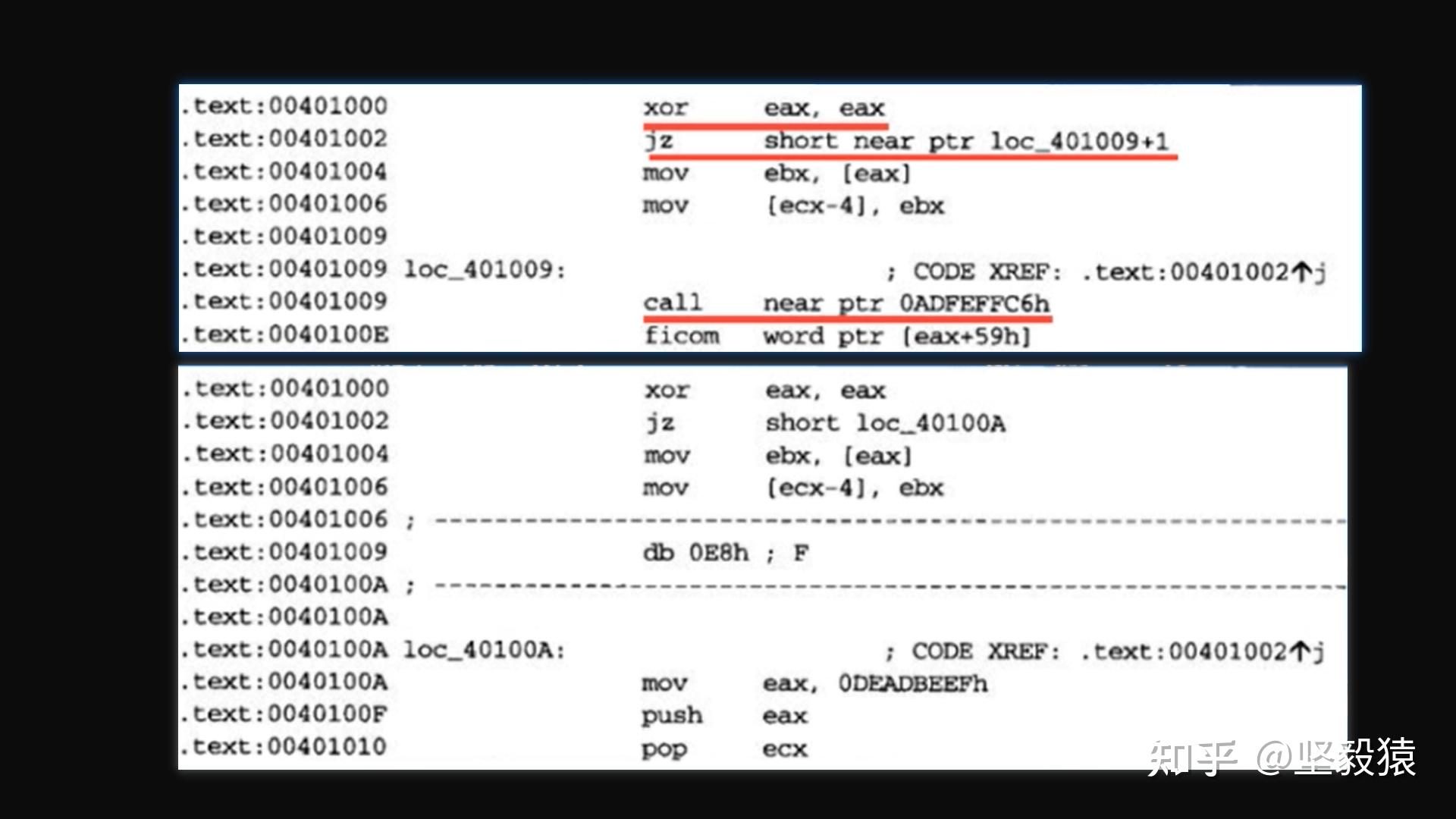 xor eax, eax
jz short near ptr loc_40100A
构成了一个绝对跳转(在40100A前的都不会执行)。但反汇编编译器没有识别,继续对jz后面的指令比如0401009处的进行反汇编,出错。动态计算目标地址递归下降反汇编的缺陷是无法获得动态计算目标地址 除非使用脚本或者模拟器来模拟执行动态计算目标地址可以用来干扰IDA导致无法得知目标地址,无法得到这部分反汇编代码 使用一个调用语句将个返回地址压入栈中,然后这个返回地址直接由栈进入寄存器,再给寄存器加上一个常量值,得到最后的目标地址; xor eax, eax
jz short near ptr loc_40100A
构成了一个绝对跳转(在40100A前的都不会执行)。但反汇编编译器没有识别,继续对jz后面的指令比如0401009处的进行反汇编,出错。动态计算目标地址递归下降反汇编的缺陷是无法获得动态计算目标地址 除非使用脚本或者模拟器来模拟执行动态计算目标地址可以用来干扰IDA导致无法得知目标地址,无法得到这部分反汇编代码 使用一个调用语句将个返回地址压入栈中,然后这个返回地址直接由栈进入寄存器,再给寄存器加上一个常量值,得到最后的目标地址;  或者将寄存器中计算出来的返回地址移入栈顶部,然后返回指令(ret)将控制权转交给计算得出的位置。这些情况下,分析人员必须动手运行代码,才能确定程序的具体控制路径。OLLVM混淆LLVM LLVM命名最早源自于底层虚拟机(Low Level VirtualMachine)的缩写,目前LLVM就是该项目的全称。LLVM核心库提供了与编译器相关的支持可以作为多种语言编译器的后台来使用。能够进行程序语言的编译期优化、链接优化、在线编译优化、代码生成。LLVM的项目是一个模块化和可重复使用的编译器和工具技术的集合。LLVM是伊利诺伊大学的一个研究项自,提供一个现代化的,基于SSA的编译策略能够同时支持静态和动态的任意编程语言的编译目标。自那时以来,已经成长为LLVM的主干项目,由不同的子项目组成,其中许多正在生产中使用的各种商业和开源的项目,以及被广泛用于学术研究。OLLVM (Obfuscator-LLVM)是瑞士西北应用科技大学安全实验室于2010年6月份发起的个项自,该项自旨在提供一套开源的针对LLVM的代码混淆工具,以增加对逆向工程的难度。OLLVM适用LLVM支持的所有语言(C,C++,Objective-C , Ada和 Fortran)和目标平台(x86, x86-64,PowerPC, PowerPC64,ARM,Thumb,SPARC,Alpha,CellsPU,MIPS,MSP430,SystemZ和XCore)混淆的方法有:控制流平展模式 control Flow Flattening控制流平展模式可以完全改变程序原本的控制流图经FLA(CCF)模式混淆后程序的执行流程已经被打乱,出现许多代码分支简而言之,增加很多条件分支指令替换模式 Instructions Substitution指令替换摸式主要是将正常的运算操作+,-,*,/,&,|等替换成功能相等但表达更复杂的形式简而言之,把简单的运算变成复杂的运算控制流伪造模式 Bogus Control FIow控制流伪造模式也是对程序的控制流做操作与CFF不同的是,BCF模式会在原代码的块前后随机插入不确定的代码块,然后新代码块再通过条件判断跳转原代码块中。甚至原代码块可能会被克隆并插入随机的垃圾指令。同一份代码多次BCF模式的混淆时,得到的是不同混淆效果。原本简单的if else分支代码变得异常复杂,加大了逆向的难度。简而言之:不仅会打乱流程,还会添加花指令利用OLLVM混淆Android Native代码编译OLLVM环境 虚拟机 ubuntu 16.04_64位,4核,16G内存,编译耗时30min左右安装gitl和cmake: sudo apt-get install gitsudo apt-get install cmake下载和编译ollvm下载 cd ~/mkdir workspacecd workspacegit clone -b llvm-4.0 https://github.com/obfuscator-llvm/obfuscator.git(不稳定,下载不下来就换网或者用VPN)编译 mkdir buildcd buildcmake -DCMAKE_BUILD_TYPE=Release ../obfuscator/,如果出错,换下面命令 或者将寄存器中计算出来的返回地址移入栈顶部,然后返回指令(ret)将控制权转交给计算得出的位置。这些情况下,分析人员必须动手运行代码,才能确定程序的具体控制路径。OLLVM混淆LLVM LLVM命名最早源自于底层虚拟机(Low Level VirtualMachine)的缩写,目前LLVM就是该项目的全称。LLVM核心库提供了与编译器相关的支持可以作为多种语言编译器的后台来使用。能够进行程序语言的编译期优化、链接优化、在线编译优化、代码生成。LLVM的项目是一个模块化和可重复使用的编译器和工具技术的集合。LLVM是伊利诺伊大学的一个研究项自,提供一个现代化的,基于SSA的编译策略能够同时支持静态和动态的任意编程语言的编译目标。自那时以来,已经成长为LLVM的主干项目,由不同的子项目组成,其中许多正在生产中使用的各种商业和开源的项目,以及被广泛用于学术研究。OLLVM (Obfuscator-LLVM)是瑞士西北应用科技大学安全实验室于2010年6月份发起的个项自,该项自旨在提供一套开源的针对LLVM的代码混淆工具,以增加对逆向工程的难度。OLLVM适用LLVM支持的所有语言(C,C++,Objective-C , Ada和 Fortran)和目标平台(x86, x86-64,PowerPC, PowerPC64,ARM,Thumb,SPARC,Alpha,CellsPU,MIPS,MSP430,SystemZ和XCore)混淆的方法有:控制流平展模式 control Flow Flattening控制流平展模式可以完全改变程序原本的控制流图经FLA(CCF)模式混淆后程序的执行流程已经被打乱,出现许多代码分支简而言之,增加很多条件分支指令替换模式 Instructions Substitution指令替换摸式主要是将正常的运算操作+,-,*,/,&,|等替换成功能相等但表达更复杂的形式简而言之,把简单的运算变成复杂的运算控制流伪造模式 Bogus Control FIow控制流伪造模式也是对程序的控制流做操作与CFF不同的是,BCF模式会在原代码的块前后随机插入不确定的代码块,然后新代码块再通过条件判断跳转原代码块中。甚至原代码块可能会被克隆并插入随机的垃圾指令。同一份代码多次BCF模式的混淆时,得到的是不同混淆效果。原本简单的if else分支代码变得异常复杂,加大了逆向的难度。简而言之:不仅会打乱流程,还会添加花指令利用OLLVM混淆Android Native代码编译OLLVM环境 虚拟机 ubuntu 16.04_64位,4核,16G内存,编译耗时30min左右安装gitl和cmake: sudo apt-get install gitsudo apt-get install cmake下载和编译ollvm下载 cd ~/mkdir workspacecd workspacegit clone -b llvm-4.0 https://github.com/obfuscator-llvm/obfuscator.git(不稳定,下载不下来就换网或者用VPN)编译 mkdir buildcd buildcmake -DCMAKE_BUILD_TYPE=Release ../obfuscator/,如果出错,换下面命令  cmake -DCMAKE_BUILD_TYPE=Release -DLLVM_INCLUDE_TESTS=OFF ../obfuscator/ cmake -DCMAKE_BUILD_TYPE=Release -DLLVM_INCLUDE_TESTS=OFF ../obfuscator/  make -j4(并行编译任务,一般为CPU核数的双倍) make -j4(并行编译任务,一般为CPU核数的双倍)  添加环境变量,方便使用命令行在任何位置都能直接调用ls bin/clangexport PATH=~/workspace/build/bin/:$PATHecho $PATH 添加环境变量,方便使用命令行在任何位置都能直接调用ls bin/clangexport PATH=~/workspace/build/bin/:$PATHecho $PATH  使用OLLVM没有混淆前的代码mkdir hellocd hellovim hello.c#include
int main()
{
int a=5;
if(a 使用OLLVM没有混淆前的代码mkdir hellocd hellovim hello.c#include
int main()
{
int a=5;
if(a未混淆的  OLLVM指令替换模式把简单的运算变成复杂的运算 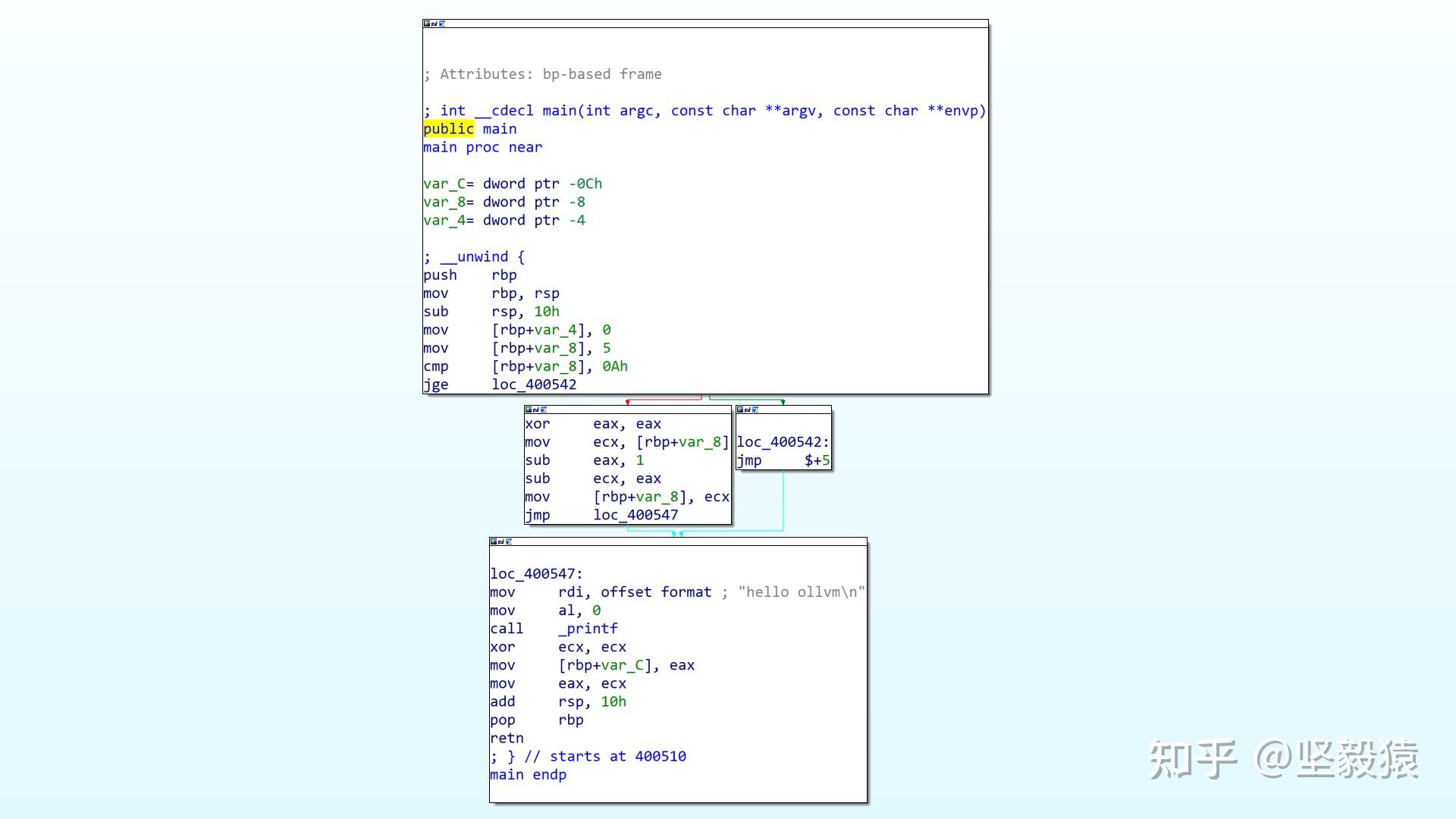 OLLVM控制流平展模式增加很多条件分支  OLLVM控制流伪造模式不仅会打乱流程,还会添加花指令  OLLVM三种混淆模式同时作用  加壳壳壳是指在一个程序的外面再包裹上另外一段代码,保护里面的代码不被非法修改或反编译的程序。它们一般都是先于程序运行,拿到控制权,然后完成它们保护软件的任务。  壳的加载过程: 保存现场(pushad/popad,pushfd/popfd)获取壳自己需要的API地址(LoadLibrary+ GetProcAddress)解密/解压原程序各个区块IAT的初始化重定位Hook-API(为了让程序解密之后,继续能和壳进行通信,程序执行这些API的时候重新回到壳里面)跳到OEP(原始入口点)壳的分类压缩壳:UPX UPX是一个以命令行方式操作的可执行文件经典免费压缩程序,压缩算法自己实现,速度极快。 壳的加载过程: 保存现场(pushad/popad,pushfd/popfd)获取壳自己需要的API地址(LoadLibrary+ GetProcAddress)解密/解压原程序各个区块IAT的初始化重定位Hook-API(为了让程序解密之后,继续能和壳进行通信,程序执行这些API的时候重新回到壳里面)跳到OEP(原始入口点)壳的分类压缩壳:UPX UPX是一个以命令行方式操作的可执行文件经典免费压缩程序,压缩算法自己实现,速度极快。(开源)主页:http://upx.sourceforge.net ASPack ASPack是Win32可执行文件庄缩软件,可压缩Windows 32位可执行文件(.exe)以及库文件(.dll、.ocx),文件压缩比率40%~70% 主页:http://www.aspack.com 加密壳:a. ASProtect ASProtect是一款非常强大的Windows 32位保护工具,开发者是俄国人Aexey Solodovnikov,拥有压缩、加密、反踪代码、反-反汇编代、CRC校验和花指令等保护措施。使用Blowfish、Twofish、TEA等强劲的加密算法,还用RSA1024作为注册整钥生成器。它还通过API钩子(API hooks,包括Import hooks ( GPA hook)和Eport hooks)与加壳的程序进行通信。其至用到了多态变形引擎(Polymorphic Engine)反Apihook代码(Anti-Apihook Code)和BPE32的多态变形引擎(RPF32的Polvmornhic Engine).ASProtect为软件开发人员提供SDK(在自己代码内部打桩),实现加密程序内外结合。 主页:http://www.aspack.com/ b. Armadillo Armadillo(穿山甲),是一款应用面较广的壳,可以运用各种手段来保护你的软件,同时也可以为软件加上种种限制,包括时间、次数,启动画面等等。很多商用软件采用其加壳。Armadllo中比较强太的保护选项是Nanomites保护(即cc保护),用的好能提高强度,其他选项没什么强度。 主页:http://www.siliconrealms.com/ c. Themida Themida是oreans(西班牙著名的软性系统保护公司)的一款商业壳。Themida 1.1以前版本带驱动,稳定性有些影响。Themida最大特点就是虚拟机保护技术,在程序中用SDK将关键的代码让Themmida用虚拟机保护起来。Themida的缺点是生成的软件有些大。Winkcense壳和Themida是同一公司的一个系列产品,主要多了一个协议,可以设定使用时间,运行次数等功能,两者核心保护是一样的 主页:http://www.oreans.com d. VMProtect VMProtect是一款纯虚拟机保护软件,是当前最强的虚拟机保护软件,经VMProtect处理过的代码,还原难度极大。流行的做法,先用VMProtect将核心代码处理一下(VMProtect的稳定性不是特别高,如果对整个程序进行加壳会影响程序的执行效率,折中方案:用SDK只对关键的代码处理),再选用—款兼容性好的壳保护。比如继续用Asprotect, Themida等加壳软件进一步保护。VMP与传统的壳(压缩,加密)相比,它会修改目标,让目标的部分指令(形成虚拟机下的字节码)在它创建的虚拟机环境下运行,虚拟环境中无操作数比较指令、条件跳转和无条件跳转指令vmp的虚拟机其实是一个字节码解释器,循环的读取指令并执行虚假跳转和垃圾指令, vmp会使用大量的虚拟跳转和垃圾指令将原有简单的代码变得复杂,类似OLLVMvmp中只有一个逻辑运算指令nor,它可以模拟not and or xor 四个逻辑运算指令,进一步加大逆向分析的难度。 主页:http://www.VMProtect.ru UPX加壳加壳过程: 下载工具包:http://upx.sourceforge.net cmd以管理员身份运行,upx.exe Xxx.exe 加upx壳经过UPX压缩的win32/pe文件,包含三个区段:UPX0,UPX1,.rsrc或UPX0,UPX1,UPX2(原文件无资源时)。 UPX0:在文件中没有内容它的Virtual size加上UPX1的构成了原文件全部区段需要的内存空间,相当于把原来区段合并了。UPX1:起始位置为需解压缩的源数据,目标地址为UPX0基址。紧接着源数据块是UPX stub,即壳代码。典型的pushad/popad结构,常用ESP定律找到OEP来脱UPX。.rsrc/UPX2:原文件有资源时,含原资源段的完整头部和极少部分资源数据(类型为ICON、 GROUP ICON、VERSION和MANIFEST),以保证explorer.exe能正常显示win32/pe文件图标、版本信息。还有就是UPX自己的Imports内容,导出表的库名和函数名(如果有)。用IDA打开加了UPX壳的.exe可以发现: 很多数据IDA无法进行反汇编,看到的都是压缩的数据  导出表的函数不属于程序本身,而是壳要用到的函数  没有.text和.data节,取而代之是UPX0,UPX1  VMP加壳方法1:加壳时,须告诉VMProtect要加密的代码地址(可以用调试器,如OllyDbg跟踪)然后将该地址添加到VMProtect 。方法2:由于VMP支持SDK,可以编程时插入一个标记,然后在加密时,VMProtect会认出这些标记,并在有标记的地方进行保护。#define VMPBEGIN \ __asm_emit 0xEB \ __asm_emit 0x10 \ __asm_emit 0x56 \ __asm_emit 0x4D \ __asm_emit 0x50 \ __asm_emit 0x72 \ __asm_emit 0x6F \ __asm_emit 0x741 \ __asm_emit 0x65 \ __asm_emit 0x63 \ __asm_emit 0x74 \ __asm_emit 0x20 \ __asm_emit 0x62 \ __asm_emit 0x65 \ __asm_emit 0x67 \ __asm_emit 0x69 \ __asm_emit 0x6E \ __asm_emit 0x00 #define VMPEND \ __asm__emit 0xEB \ __asm_emit 0x0E \ __asm_emit 0x56 \ __asm_emit 0x4D \ __asm_emit 0x50 \ __asm_emit 0x72 \ __asm_emit 0x6F \ __asm_emit 0x74 \ __asm_emit 0x65 \ __asm_emit 0x63 \ __asm_emit 0x74 \ __asm_emit 0x20 \ __asm_emit 0x65 \ __asm_emit 0x6E \ __asm_emit 0x64 \ __asm_emit 0x00 //VMProtect 的SDK 标志 VMPBEGIN //要加密的核心代码片断 VMPEND 用IDA打开加了VMP壳的.exe可以发现:很多数据IDA无法进行反汇编,看到的都是压缩的数据  导出表的函数不属于程序本身,而是壳要用到的函数 导出表的函数不属于程序本身,而是壳要用到的函数  多了.vmp0,.vmp1的节 多了.vmp0,.vmp1的节  VMP加壳实战开发一个简单的MFC程序void CVMPDemoDlg::OnBnClickedOk()
{
// TODO: 在此添加控件通知处理程序代码
//CDialogEx::OnOK();
MessageBox(_T("hello VMP"), _T("VMP"), MB_OK);
}
没加壳之前逆向分析 可以直接搜索关键字hello 就可以找到MessageBox函数,按F5可以查看到反C代码 VMP加壳实战开发一个简单的MFC程序void CVMPDemoDlg::OnBnClickedOk()
{
// TODO: 在此添加控件通知处理程序代码
//CDialogEx::OnOK();
MessageBox(_T("hello VMP"), _T("VMP"), MB_OK);
}
没加壳之前逆向分析 可以直接搜索关键字hello 就可以找到MessageBox函数,按F5可以查看到反C代码   加壳再逆向分析 对照实验 3.1 安装VMProtect,安装目录获取库文件:VMProtect Ultimate\Include\C VMProtectSDK.h 给应用程序加壳VMProtectDDK.h 给驱动加壳VMProtect Ultimate\Lib\Windows\ VMProtectDDK32.libVMProtectDDK32.sysVMProtectDDK64.libVMProtectDDK64.sysVMProtectSDK32.dllVMProtectSDK32.libVMProtectSDK64.dllVMProtectSDK64.lib 加壳再逆向分析 对照实验 3.1 安装VMProtect,安装目录获取库文件:VMProtect Ultimate\Include\C VMProtectSDK.h 给应用程序加壳VMProtectDDK.h 给驱动加壳VMProtect Ultimate\Lib\Windows\ VMProtectDDK32.libVMProtectDDK32.sysVMProtectDDK64.libVMProtectDDK64.sysVMProtectSDK32.dllVMProtectSDK32.libVMProtectSDK64.dllVMProtectSDK64.lib3.2 拷贝到工程目录下 - 把头文件拷贝到源代码目录下 - 把.dll/.sys和.lib文件拷贝到源代码目录下 3.3 包含头文件和加载.lib文件,给关键代码加上VMP壳 #include "VMProtectSDK.h" #pragma comment(lib,"VMProtectSDK32.lib") //关键代码,加上VMP壳 void CVMPDemoDlg::OnBnClickedOk() { VMProtectBegin("tagname"); // TODO: 在此添加控件通知处理程序代码 //CDialogEx::OnOK(); MessageBox(_T("hello VMP"), _T("VMP"), MB_OK); VMProtectEnd(); } /// 其他标记 //开始保护处标记 VMProtectBegin( const char *); //开始虚拟化代码处标记(包括保护设置) VMProtectBeginvirtualization( const char *); //开始变异代码处标记(包括保护设置) VMProtectBeginMutation(const charn *) //开始虚拟+代码变异标记处 VMPrckctBeginLltra(cont char *) VMProtectBeginvitualizationLoekEykey(const char *); VMProtectBegimUltraLockEykKey(const char *); //保护结束处标记 VMRrotectEnd(void) //检测调试 BOOL VKMProtectlsDebuggerPresent(BOOL); //检测虚拟机 BOOL VMProtectlsValidlmageCRC(void) //映像文件CRC校验 BOoL VMProtectisValidimageCRC(void) //解密被保护的名为字符串A,A表示是多字节字符串 char * VMProtectDecryptStringA(const char *value); //解密被保护的名为字符串W,W表示宽字节字符串 wchar_t * VMProtectDecryptStringW(const wchar_t *value); ///eg //char Decrypt(chtar key, char* buff, long len ){} Decrypt(VMProtectDecryptStringA("mm1 23456"),//此时密文密钥key被解密 buff, 256 );3.4 编译出release版本后,用VMProtect进行加壳   3.5 用IDA逆向分析 可以直接搜索关键字hello 已经看不到结果了 去模糊化方法基于IDC脚本:使用IDCC执行每一项CPU操作,模拟程序执行,修该程序数据库。 不足:复杂的情况(加了upx壳,aspack壳,或者版本更新,脚本不适用了)缺乏通用性模拟器去模糊:ida-x86emu(ALT+F8启动) 没有Linux或者MacOS,也可以再Windows上用模拟器ida-x86emu去模拟执行在模拟程序运行的过程中,自然把花指令全部去掉,直接把正确的反汇编代码分析出来 去模糊化方法基于IDC脚本:使用IDCC执行每一项CPU操作,模拟程序执行,修该程序数据库。 不足:复杂的情况(加了upx壳,aspack壳,或者版本更新,脚本不适用了)缺乏通用性模拟器去模糊:ida-x86emu(ALT+F8启动) 没有Linux或者MacOS,也可以再Windows上用模拟器ida-x86emu去模拟执行在模拟程序运行的过程中,自然把花指令全部去掉,直接把正确的反汇编代码分析出来  学习《IDA Pro权威指南》 和 《IDA代码破解揭秘》 逆向分析实战脱壳原理和步骤查看是否加壳以及壳的种类 查壳工具:PEiD、ExeinfoPe查找程序的真正入口点(OEP,Original Entry Point); 如何定位OEP: https://bbs.pediy.com/thread-218605.htm 学习《IDA Pro权威指南》 和 《IDA代码破解揭秘》 逆向分析实战脱壳原理和步骤查看是否加壳以及壳的种类 查壳工具:PEiD、ExeinfoPe查找程序的真正入口点(OEP,Original Entry Point); 如何定位OEP: https://bbs.pediy.com/thread-218605.htm抓取内存映像文件 用OD加载加了壳的程序,让其运行(加了壳的程序要运行,肯定会加载入内存中,把自己的壳脱掉,所以在内存中,程序是脱了壳的),当它脱完壳的时候,找到它的OEP后,把文件从内存中Dump出来输入表重建在PE文件还在磁盘中适合IMP表和IAT表和IAT指向同一个结构体数组  一旦PE文件运行起来之后(即加载入内存之后),导入表的OriginalFirstLink依然指向INT指向一个结构体数组(存放函数名+下标),但导入表的FirstLink和IAT表指向的是新的地方(存放函数的地址,而不是函数名+下标了),所以需要为抓取内存映像文件重建输入表(也就是导入表),否则抓取内存映像文件依然无法执行(因为调用的函数都不知道) 一旦PE文件运行起来之后(即加载入内存之后),导入表的OriginalFirstLink依然指向INT指向一个结构体数组(存放函数名+下标),但导入表的FirstLink和IAT表指向的是新的地方(存放函数的地址,而不是函数名+下标了),所以需要为抓取内存映像文件重建输入表(也就是导入表),否则抓取内存映像文件依然无法执行(因为调用的函数都不知道)  EXE 的所有的导入函数信息都会写入输入表(也就是导入表)中,在PE文件映射到内存后,windows将相应的DLL文件装入,EXE文件通过输入表找到相应的DLL中的导入函数,从而完成程序的正常运行,这一动态连接的过程都是由输入表参与的。重建输入表也有专门的工具可以处理UPX脱壳OllyDbgOllyDbg常见快捷键 F8,单步执行,不进入callF7,单步执行,进入callF9(运行)F4,执行到光标处,执行循环的时候很好用,比如光标在循环外,按F4可以跳出循环CTRL+F9:执行直到返回ALT+F9:从系统领空直接返回,比如调试当前处于系统API,按ALT+F9直接执行完系统API返回F2,设置断点,int 3断点F3,装入要调试的程序Ctrl+ F2,重新开始调试程序,程序跑飞的时候用OllyDbg单步跟踪原则: 遇到近CALL 用F7遇到远CALL 用F8遇到跳转到向上地址(比如循环),光标选中下一个地址,按F4遇到大的跳转,要注意,离OEP就近了,按F8小心单步跟踪OllyDbg抓取内存映像文件 OllyDbg->插件->OllyDumpEx->Dump process 抓取内存映像文件,为下步重建输入表做准备 EXE 的所有的导入函数信息都会写入输入表(也就是导入表)中,在PE文件映射到内存后,windows将相应的DLL文件装入,EXE文件通过输入表找到相应的DLL中的导入函数,从而完成程序的正常运行,这一动态连接的过程都是由输入表参与的。重建输入表也有专门的工具可以处理UPX脱壳OllyDbgOllyDbg常见快捷键 F8,单步执行,不进入callF7,单步执行,进入callF9(运行)F4,执行到光标处,执行循环的时候很好用,比如光标在循环外,按F4可以跳出循环CTRL+F9:执行直到返回ALT+F9:从系统领空直接返回,比如调试当前处于系统API,按ALT+F9直接执行完系统API返回F2,设置断点,int 3断点F3,装入要调试的程序Ctrl+ F2,重新开始调试程序,程序跑飞的时候用OllyDbg单步跟踪原则: 遇到近CALL 用F7遇到远CALL 用F8遇到跳转到向上地址(比如循环),光标选中下一个地址,按F4遇到大的跳转,要注意,离OEP就近了,按F8小心单步跟踪OllyDbg抓取内存映像文件 OllyDbg->插件->OllyDumpEx->Dump process 抓取内存映像文件,为下步重建输入表做准备  脱壳机OllyDbg找OEP很繁琐,对于UPX壳这种简单的壳,可以使用upxshell.exe进行脱壳其他类型的脱壳ASProtect脱壳 ASProtect unpacker,PE_Kill出品,功能强大,能自动修复SDK,ASProtect2.X之前的版本完全支持。VMP脱壳 https://bbs.pediy.com/forum-88.htm 加壳脱壳精华区 脱壳机OllyDbg找OEP很繁琐,对于UPX壳这种简单的壳,可以使用upxshell.exe进行脱壳其他类型的脱壳ASProtect脱壳 ASProtect unpacker,PE_Kill出品,功能强大,能自动修复SDK,ASProtect2.X之前的版本完全支持。VMP脱壳 https://bbs.pediy.com/forum-88.htm 加壳脱壳精华区实操练习破解密钥字符密文 (密钥字符-5)^7 == 密文纯数字密文 解密数组[数字密钥作为下标] == 密文 -看雪题库 (pediy.com)看雪-安全培训|安全招聘|www.kanxue.com |
【本文地址】
今日新闻 |
推荐新闻 |